Event-Driven Architecture & Industrial Edge
Event-Driven Architecture & Industrial Edge
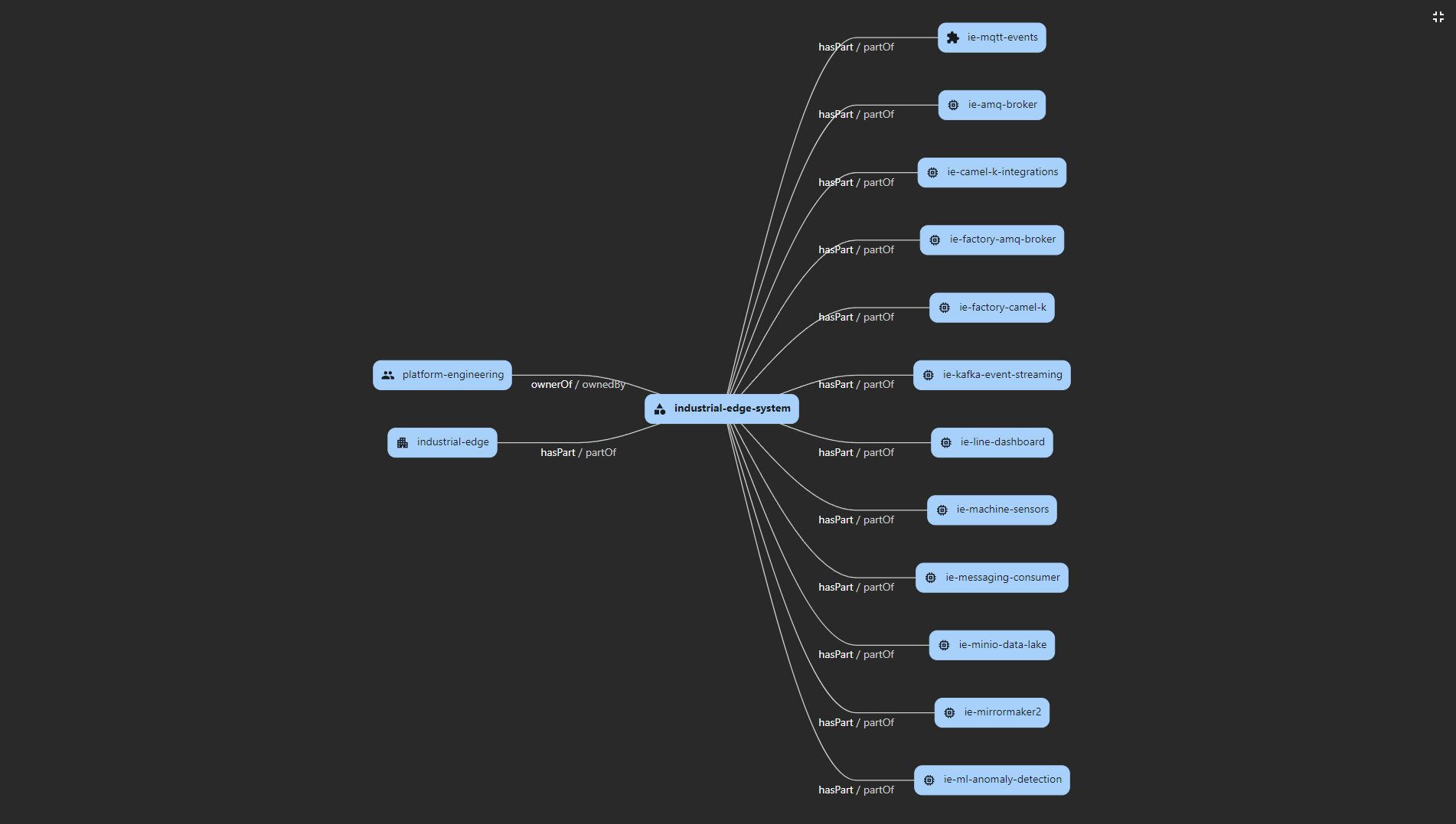
Patrón Industrial Edge
Caso de uso: Mejorar la eficiencia de fabricación y la calidad del producto con inteligencia artificial y aprendizaje automático (AI/ML) hasta el borde de la red.
| Estado de validación | Basado en | Enlaces |
|---|---|---|
Antecedentes
Los microcontroladores y otros ordenadores sencillos llevan mucho tiempo usándose en fábricas y plantas de procesamiento para supervisar y controlar la maquinaria en la fabricación moderna. El sector ha aprovechado de forma constante la tecnología para impulsar la innovación, optimizar la producción y mejorar las operaciones.
Los sistemas SCADA (Supervisory Control and Data Acquisition) han funcionado históricamente de forma independiente de la infraestructura de TI de la empresa. Sin embargo, cada vez más organizaciones reconocen el valor de integrar la tecnología operativa (OT) con la TI. Esa integración aumenta la flexibilidad de los sistemas de planta y permite adoptar tecnologías avanzadas como la IA y el aprendizaje automático. Como resultado, tareas como el mantenimiento pueden planificarse según datos en tiempo real en lugar de calendarios rígidos, mientras la capacidad de cómputo se acerca al origen de generación de datos.
Descripción general de la solución
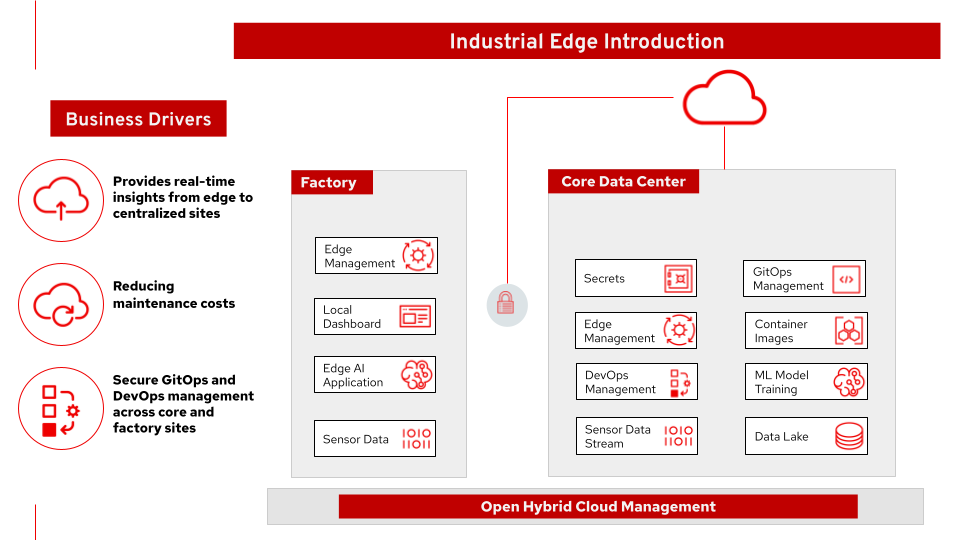
Figura 1. Visión general de la solución Industrial Edge. Aplicable a varios sectores verticales, entre ellos la fabricación.
Esta solución:
-
Ofrece información en tiempo real desde el borde hasta el centro de datos principal
-
Asegura la gestión GitOps y DevOps entre el núcleo y las plantas
-
Proporciona herramientas de AI/ML que pueden reducir costes de mantenimiento
-
Habilita Change Data Capture (CDC) para la sincronización de datos en tiempo real
-
Ofrece réplicas espejo para consultas externas sin impactar la producción
Los distintos roles de una organización tienen preocupaciones y focos distintos al trabajar con esta arquitectura distribuida de AI/ML en dos tipos lógicos de sitios:
-
El centro de datos principal. Aquí científicos de datos, desarrolladores y operaciones aplican cambios a sus modelos, código de aplicación y configuraciones.
-
Las fábricas. Aquí se despliegan aplicaciones nuevas, actualizaciones y cambios operativos para mejorar la calidad y la eficiencia en planta.
Diagramas lógicos
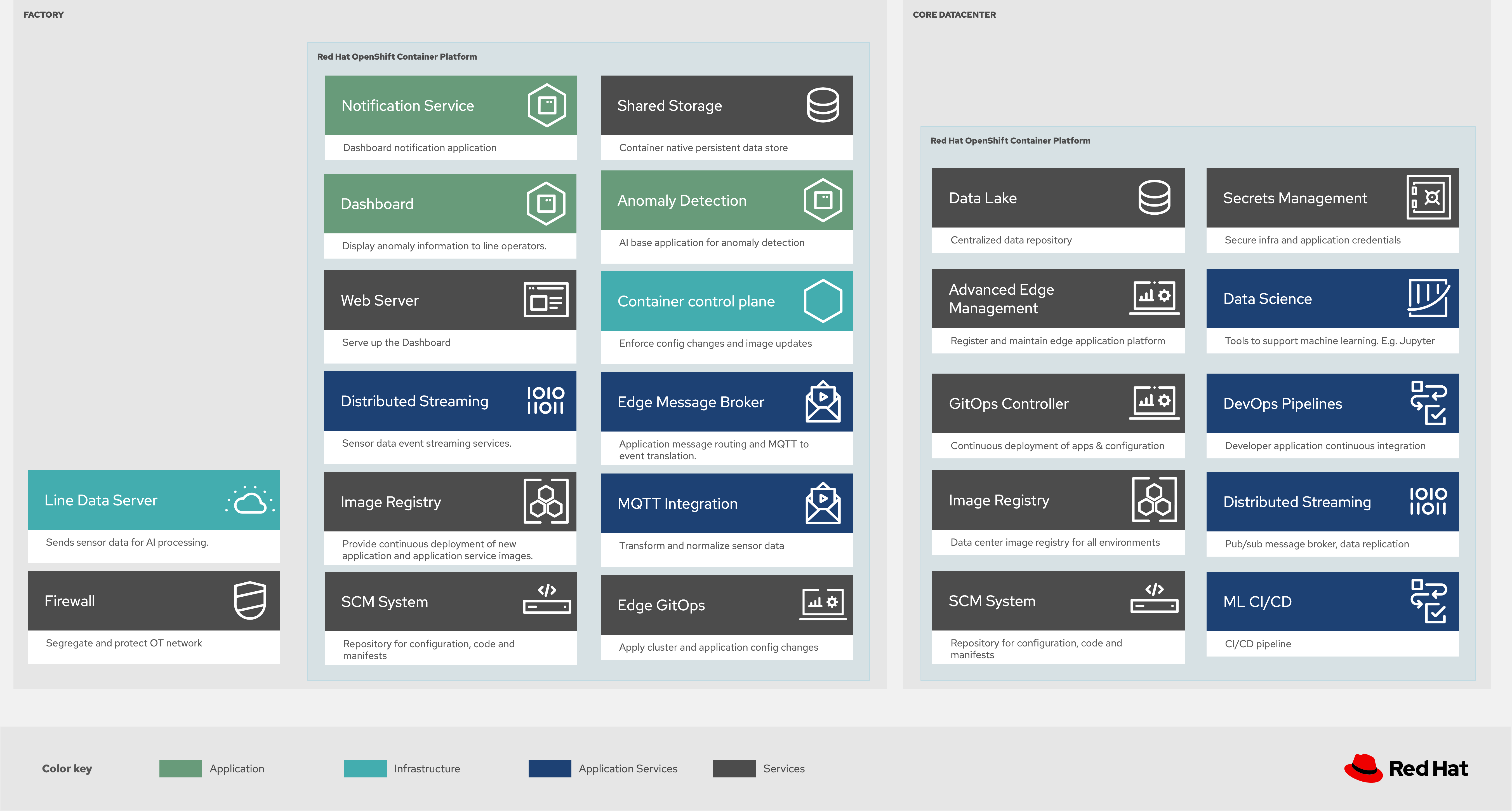
Figura 2. Solución Industrial Edge distribuida de forma lógica y física en varios sitios.
Flujos de datos generales

Figura 3. Flujos de datos generales de la solución.
Dos corrientes principales de flujo de datos:
-
Norte (borde → núcleo): Los datos de sensores y los eventos fluyen desde el borde operativo hacia el núcleo para su procesamiento centralizado. Volúmenes altos (decenas de miles de eventos por segundo) pueden hacer poco práctica la transferencia a la nube.
-
Sur (núcleo → borde): Código, configuraciones, datos maestros y modelos de ML se envían desde el núcleo al borde. Con cientos de plantas y miles de líneas de producción posibles, la automatización y la coherencia son esenciales.
La tecnología
| Tecnología | Descripción |
|---|---|
Plataforma Kubernetes lista para empresas, pensada para una estrategia de nube híbrida abierta. Ofrece una plataforma de aplicaciones coherente para gestionar nube híbrida, nube pública y despliegues en el borde. |
|
Marcos y capacidades para diseñar, construir, desplegar, conectar, asegurar y escalar aplicaciones nativas en la nube. Incluye Apache Camel, AMQ y componentes de streaming de datos. |
|
Plataforma de streaming de datos masivamente escalable, distribuida y de alto rendimiento basada en Apache Kafka. Ofrece una columna vertebral distribuida para microservicios y aplicaciones IoT con alto rendimiento y baja latencia. |
|
Plataforma de AI/ML flexible y escalable que permite a las empresas crear y entregar aplicaciones con IA a escala en entornos de nube híbrida. Incluye JupyterLab, ModelMesh y Data Science Pipelines. |
|
Controla clústeres y aplicaciones desde una única consola, con políticas de seguridad integradas. Despliega aplicaciones, gestiona varios clústeres y aplica políticas a escala. |
|
Portal de autoservicio para desarrolladores basado en Backstage. Ofrece plantillas de software, TechDocs y plugins integrados para Kafka, Topology y CI/CD. |
|
Operador de Kubernetes para Apache Kafka. Gestiona clústeres Kafka, topics, usuarios, MirrorMaker2 y KafkaConnect de forma declarativa mediante Custom Resources. |
|
Plataforma CDC de código abierto. Captura cambios a nivel de fila en bases de datos (PostgreSQL, MySQL, SQL Server) y los publica como eventos en Kafka. |
Arquitecturas
Fabricación en el borde con mensajería y ML
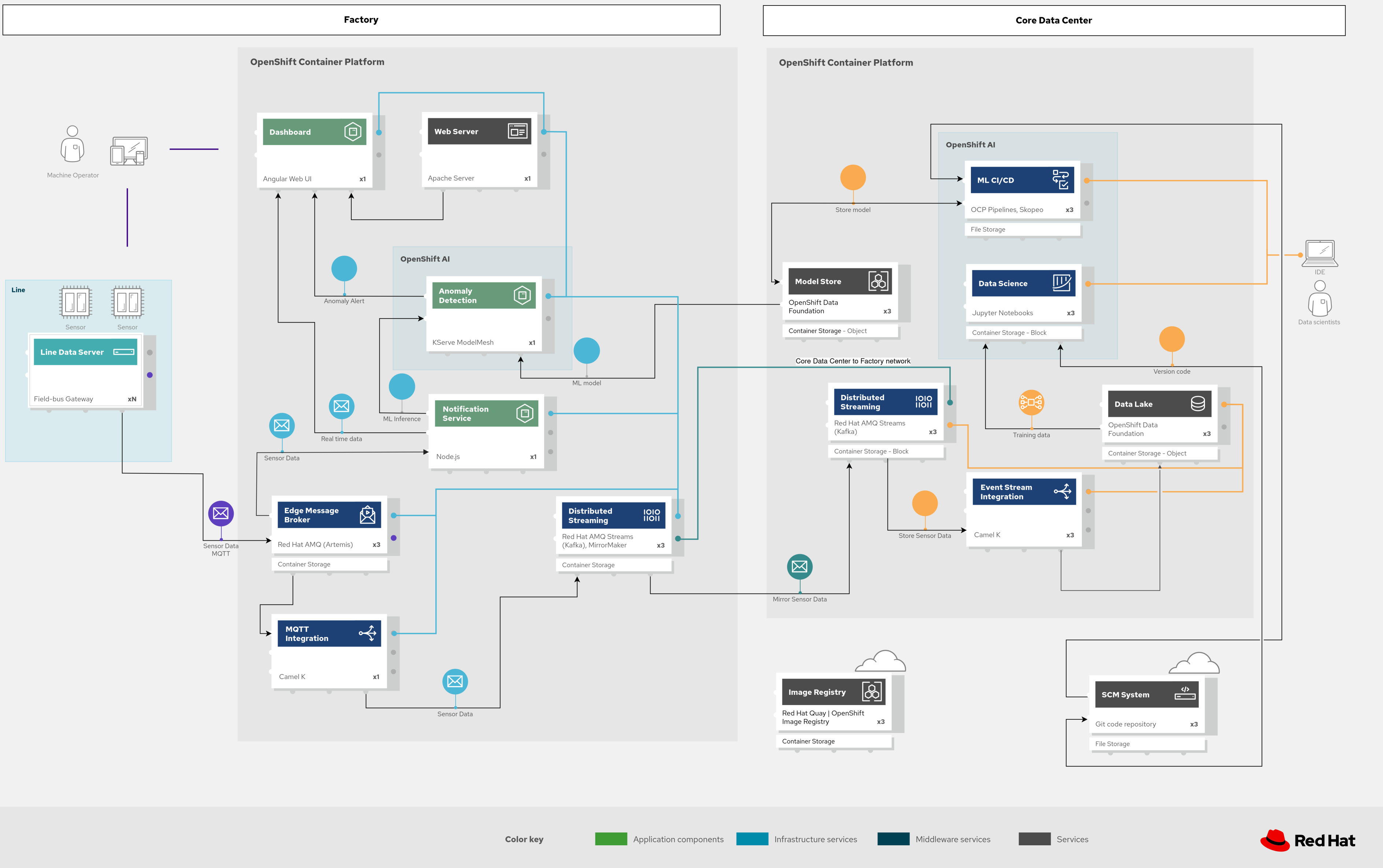
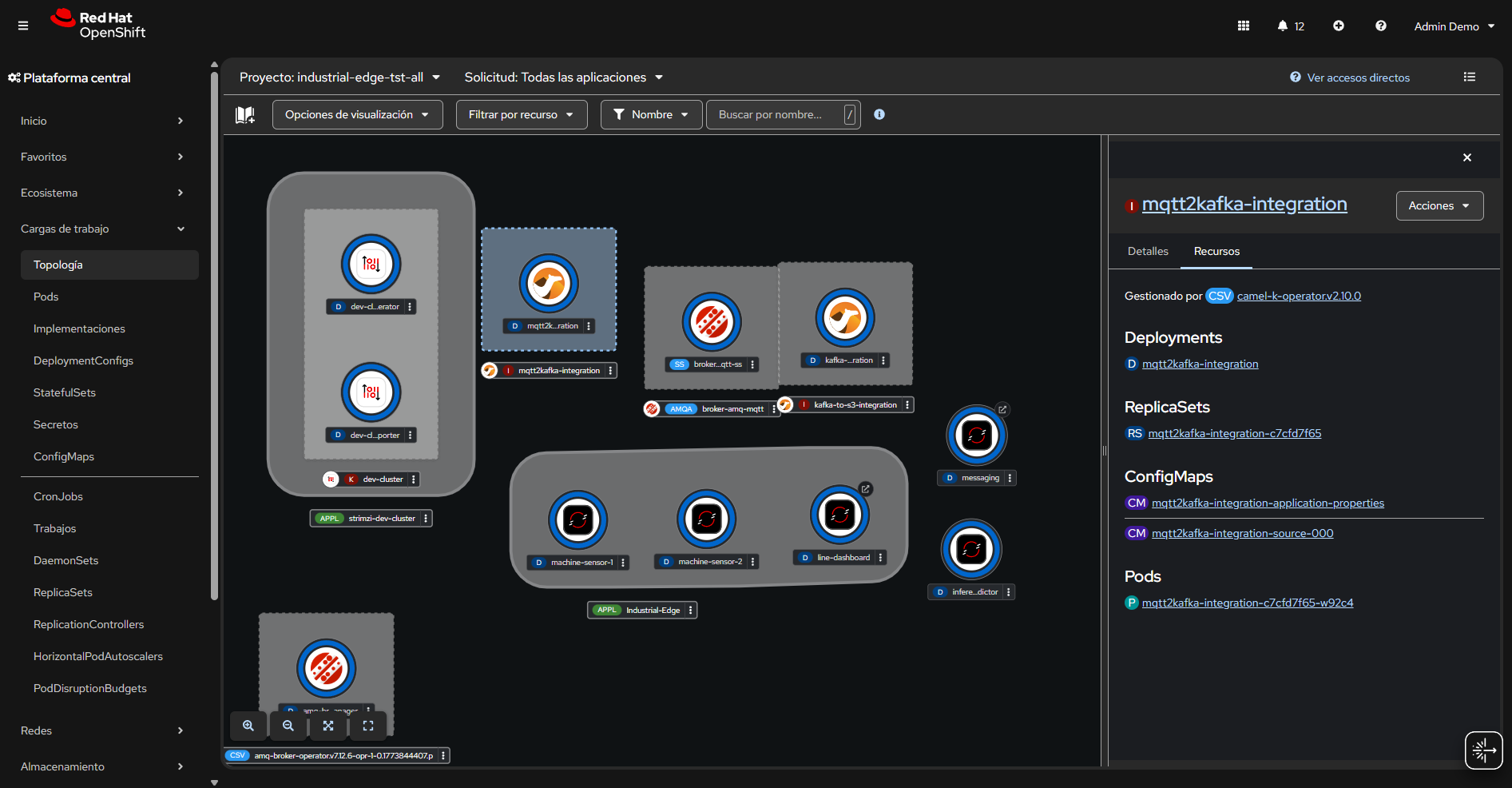
Figura 4. Solución Industrial Edge con componentes de mensajería y ML de forma esquemática.
Los datos de sensores se transmiten por MQTT a Red Hat AMQ, que los enruta con dos fines:
-
Desarrollo de modelos en el centro de datos principal (data lake → JupyterLab → entrenamiento)
-
Inferencia en vivo en los centros de datos de fábrica (IoT Consumer → ModelMesh → alertas de anomalías)
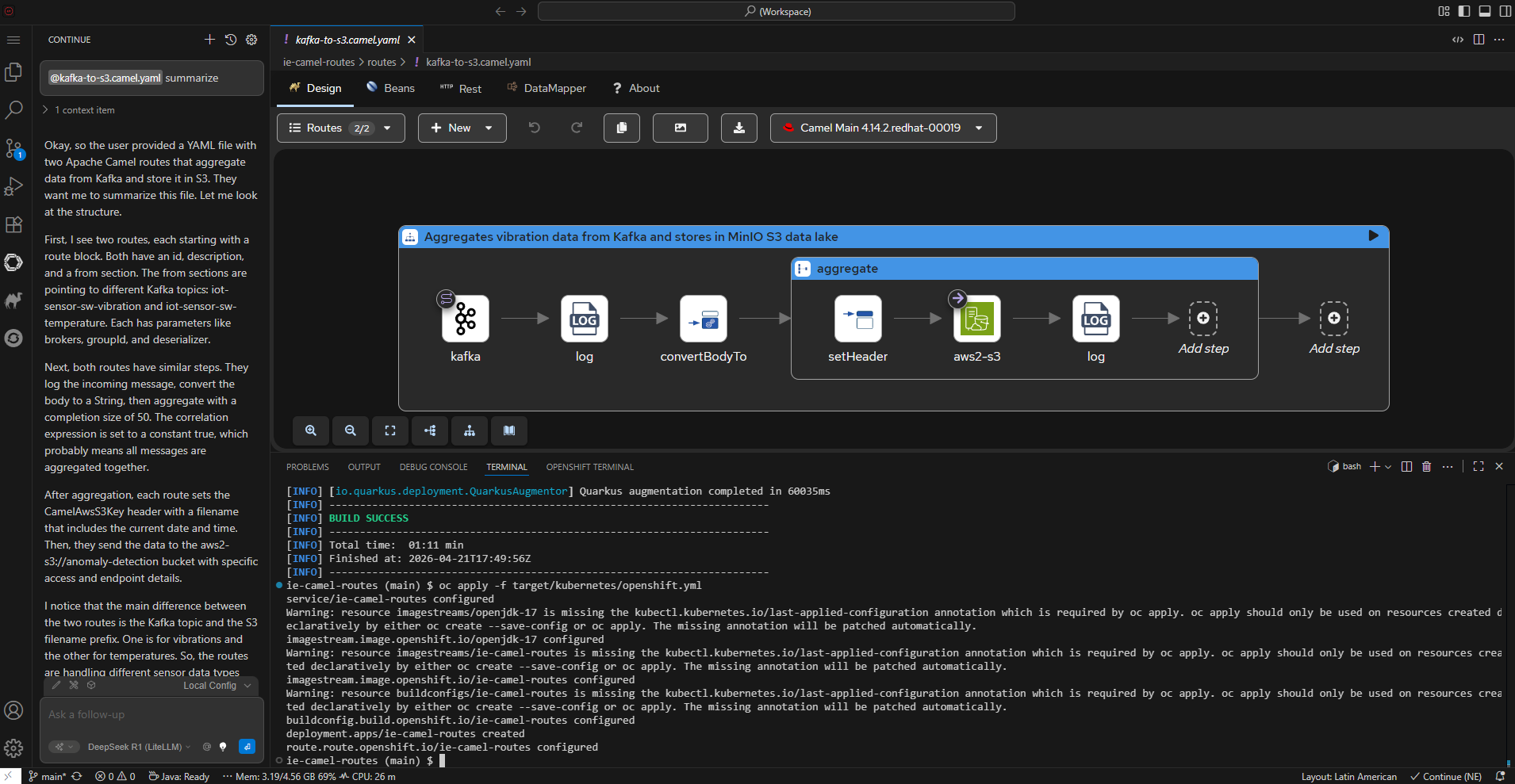
Apache Camel K proporciona integración MQTT para normalizar y enrutar datos de sensores a Kafka y luego a S3 (MinIO) para el data lake. Los científicos de datos usan las herramientas de OpenShift AI para desarrollar, entrenar y desplegar modelos.
Fabricación en el borde con GitOps
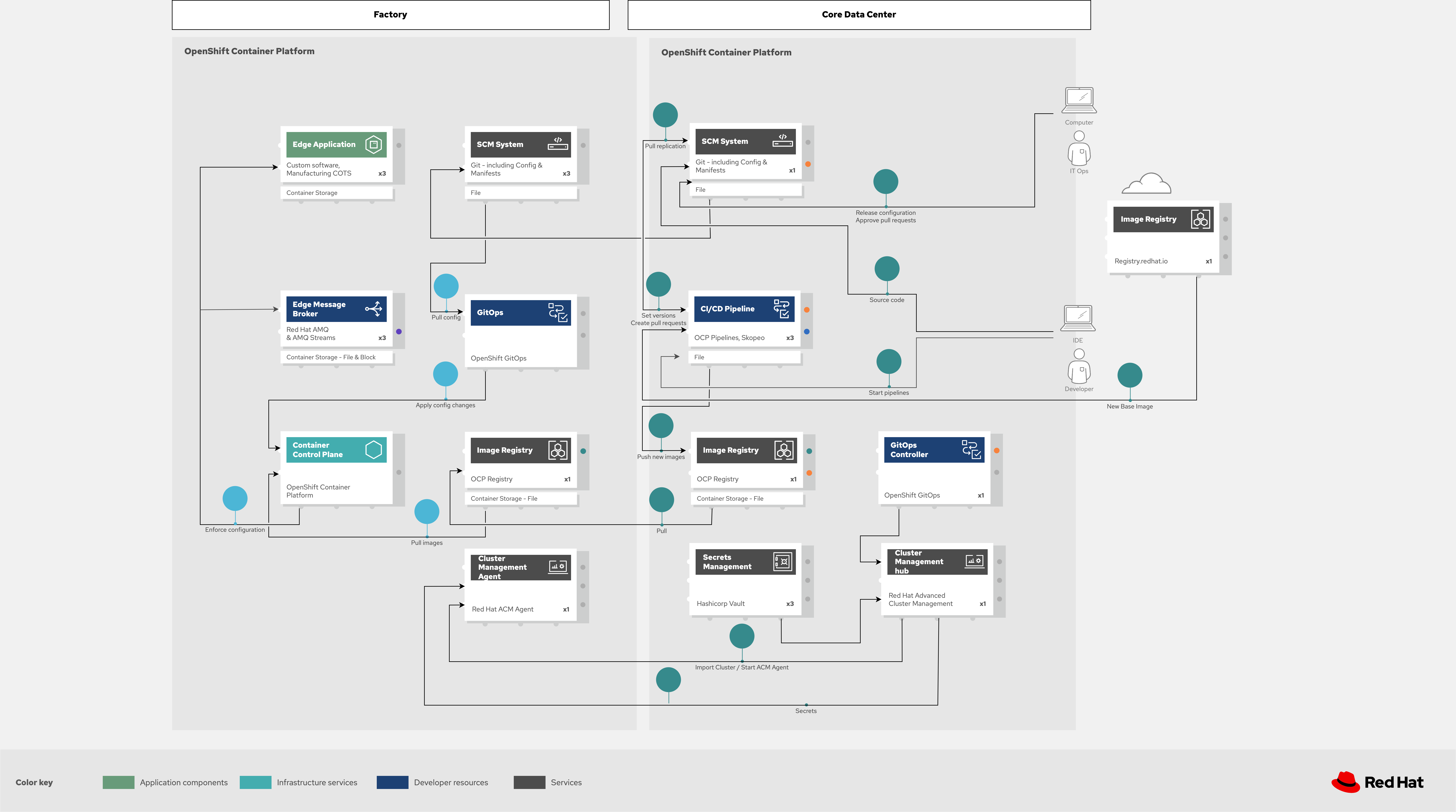
Figura 5. Solución Industrial Edge con una vista esquemática de los flujos GitOps.
GitOps ofrece un enfoque coherente y declarativo para gestionar cambios y actualizaciones del clúster entre sitios centralizados y del borde. Los cambios en configuración y aplicaciones se incorporan automáticamente a los sistemas operativos de la fábrica mediante ArgoCD.
Change Data Capture (CDC)
El CDC con Debezium captura cambios en bases de datos relacionales y los publica como eventos en un clúster Kafka dedicado. Esto permite:
-
Event sourcing y materialización de vistas
-
Sincronización entre microservicios
-
Auditoría y cumplimiento en tiempo real
-
Analítica e indexación para búsqueda
A escala de 20K dispositivos, el componente CDC gestiona ~5.000 transacciones/s en la base de datos con 5 grupos de consumidores (Camel K, notificaciones, indexador de búsqueda, analítica, registro de auditoría).
Réplicas espejo para consultas externas
KafkaMirrorMaker2 replica topics de CDC e IoT hacia un clúster espejo de solo lectura para acceso externo:
-
Consumidores de analítica/BI que leen datos sin afectar la latencia de producción
-
Replicación geográfica para equipos en otras regiones
-
Clúster de recuperación ante desastres con datos actualizados
-
Acceso externo seguro (TLS + SCRAM-SHA-512) sin exponer los clústeres internos
A escala de 20K, el espejo gestiona 13K msg/s desde 3 clústeres de origen con 7 grupos de consumidores externos.
Escenario de demostración
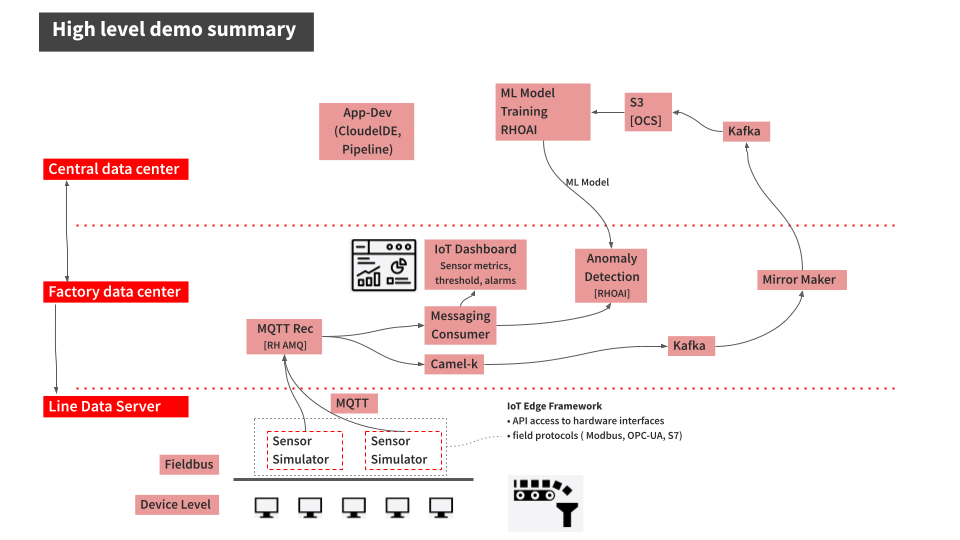
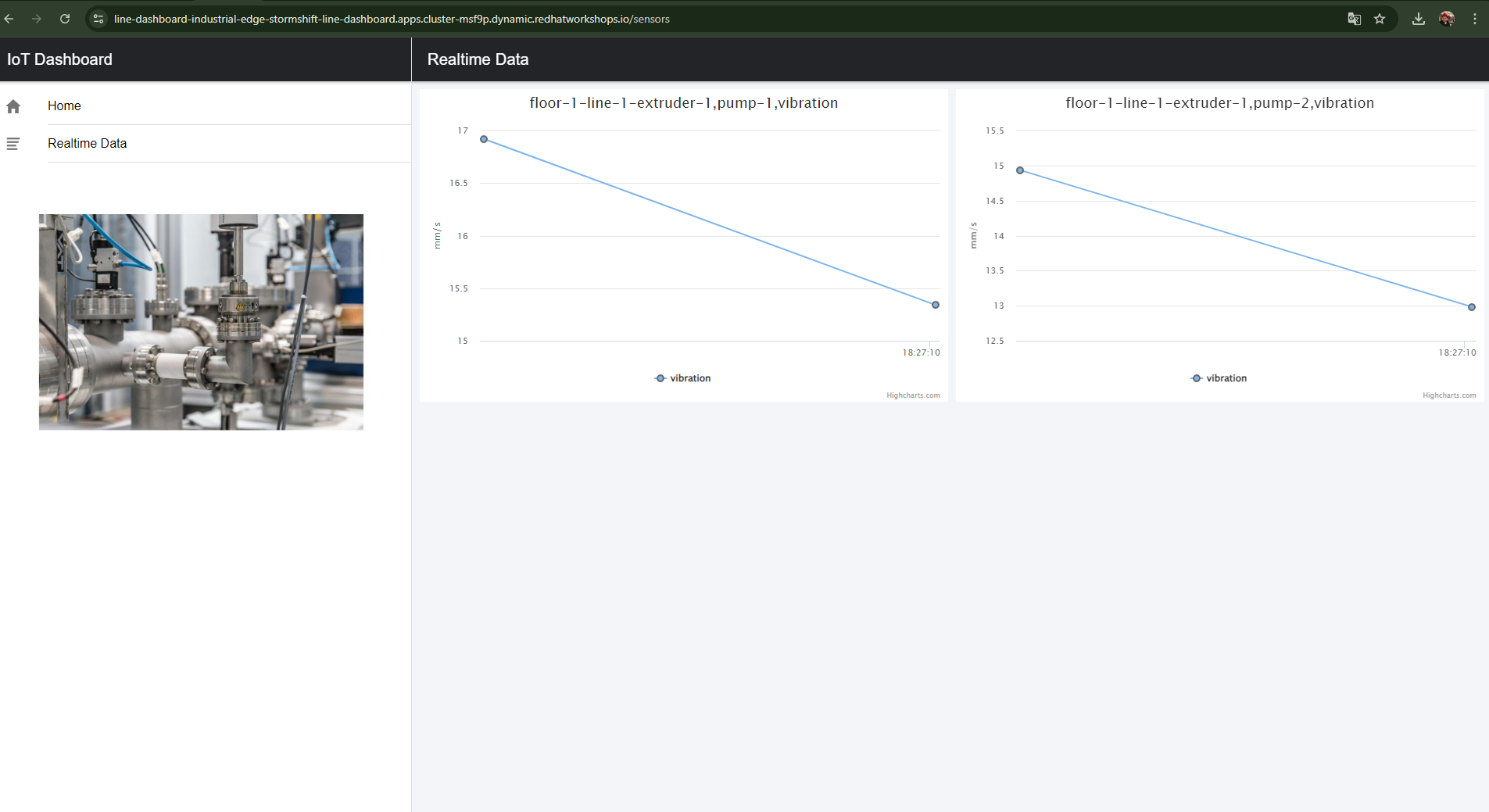
Figura 6. Resumen de alto nivel de la demo con monitorización del estado de máquinas basada en datos de sensores.
El escenario de demostración tiene tres capas:
-
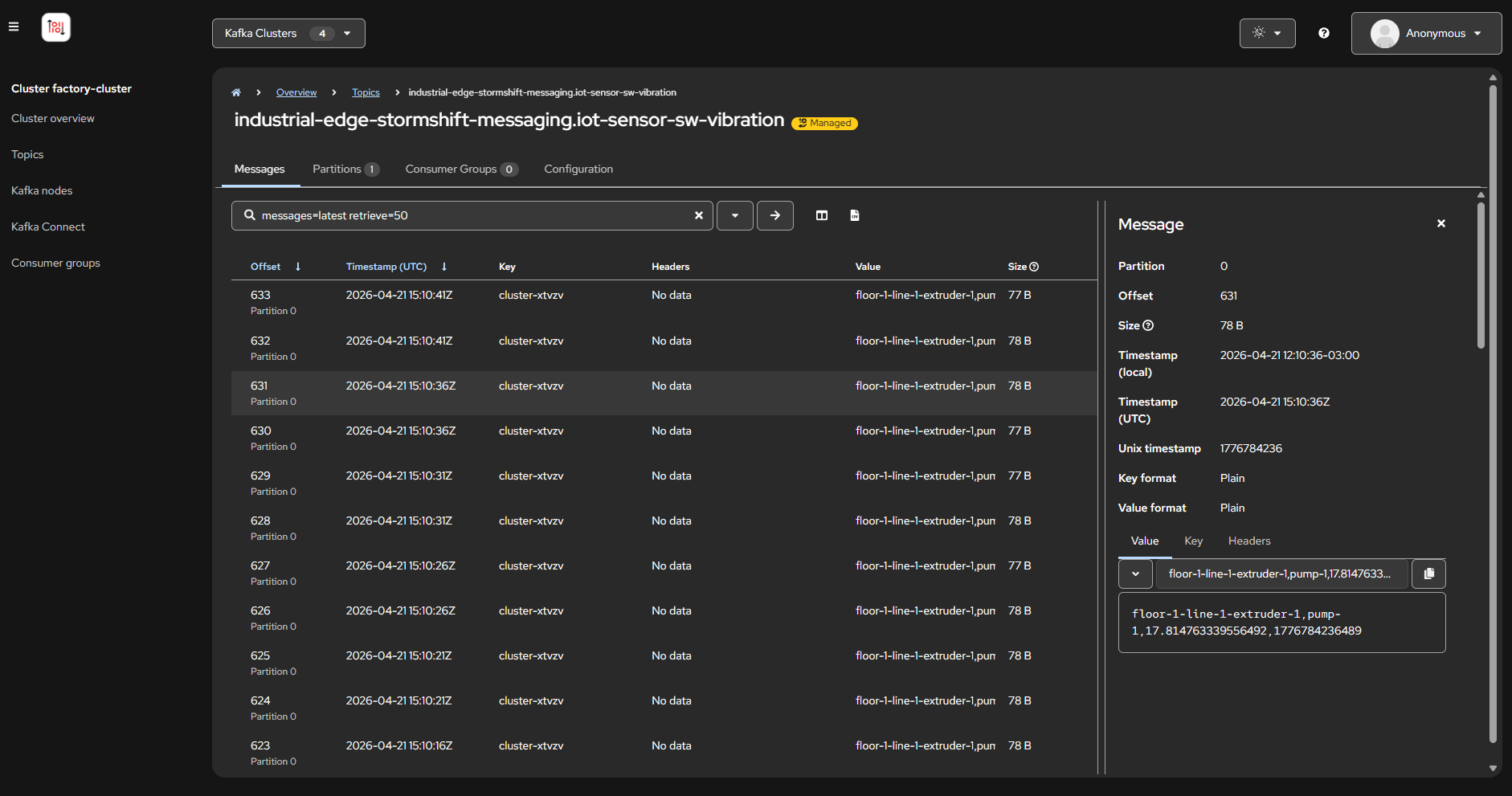
Line Data Server (borde lejano): Sensores de máquina en planta publican lecturas de vibración y temperatura por MQTT cada 5 segundos.
-
Centro de datos de fábrica (borde cercano): El broker AMQ recibe datos MQTT. Camel K hace de puente MQTT→Kafka. Kafka de fábrica hace streaming de datos. IoT Consumer alimenta ModelMesh para detección de anomalías. Line Dashboard ofrece visualización en tiempo real.
-
Centro de datos central (núcleo): El data lake en Kafka almacena datos espejados. La integración Camel K escribe en MinIO S3. OpenShift AI ofrece notebooks JupyterLab, Data Science Pipelines y servicio ModelMesh.
Qué está en ejecución
| Componente | Función | Namespace |
|---|---|---|
Machine Sensors (x4) |
Simulan lecturas de vibración y temperatura cada 5 segundos por MQTT |
|
AMQ Broker (x2) |
Broker MQTT que recibe datos de sensores en el borde de fábrica |
|
Kafka Clusters (x3) |
Clústeres Dev, Factory y Data Lake para streaming de eventos |
|
Camel K |
Puente MQTT→Kafka e integración Kafka→S3 del data lake |
|
Line Dashboard (x2) |
Visualización en tiempo real de datos de sensores y alertas de anomalías |
|
MinIO S3 |
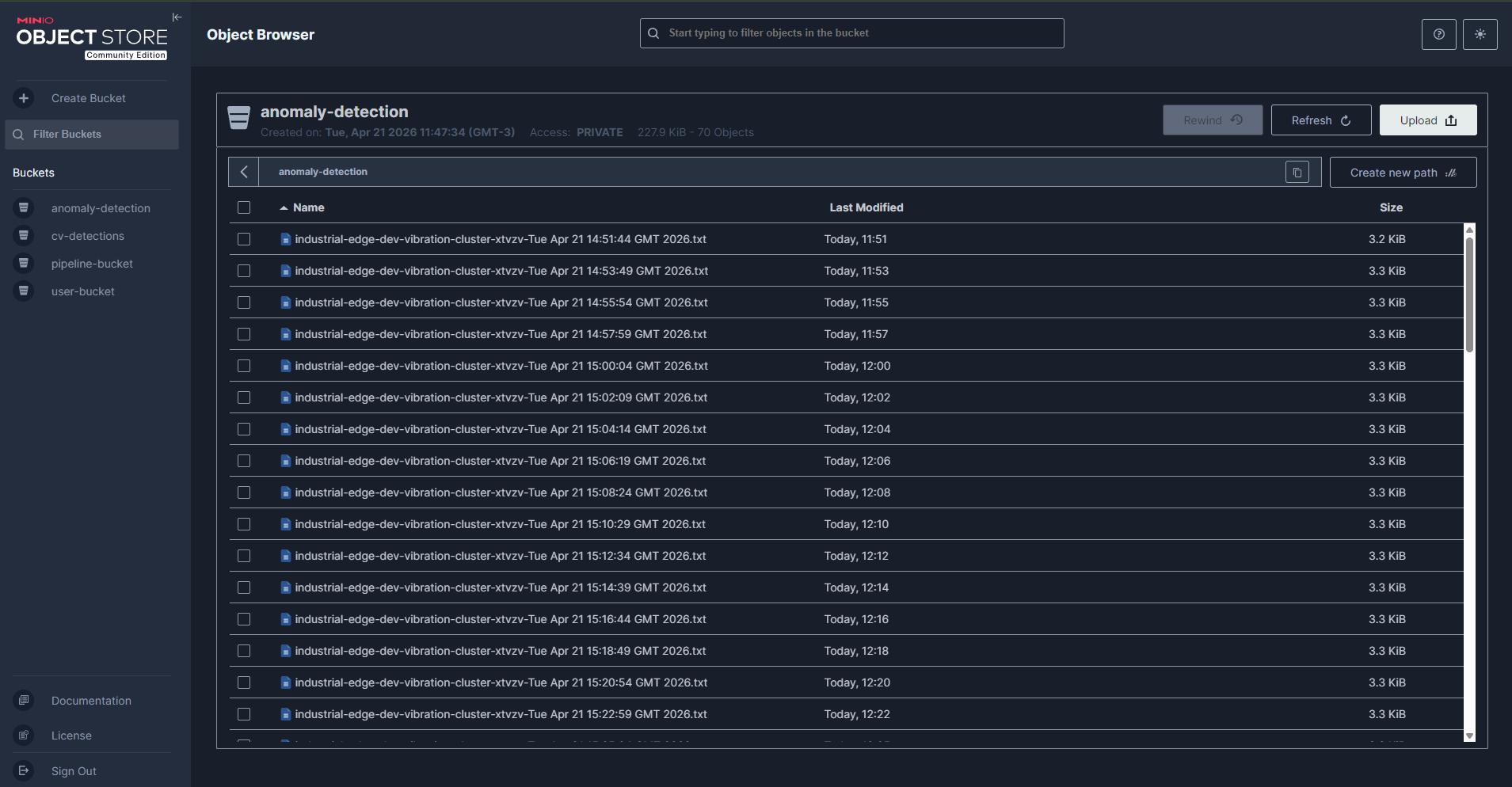
Almacenamiento de objetos para el data lake (datos de entrenamiento de modelos, artefactos) |
|
OpenShift AI |
JupyterLab + ModelMesh + Data Science Pipelines |
|
IoT Consumer (messaging) |
Backend que consume datos MQTT de sensores y los reenvía a inferencia ML |
|
Guion de la demo
Para explorar el despliegue Industrial Edge, sigue la guía del showroom:
-
Observar sensores IoT — Observa el flujo de datos de sensores en tiempo real
-
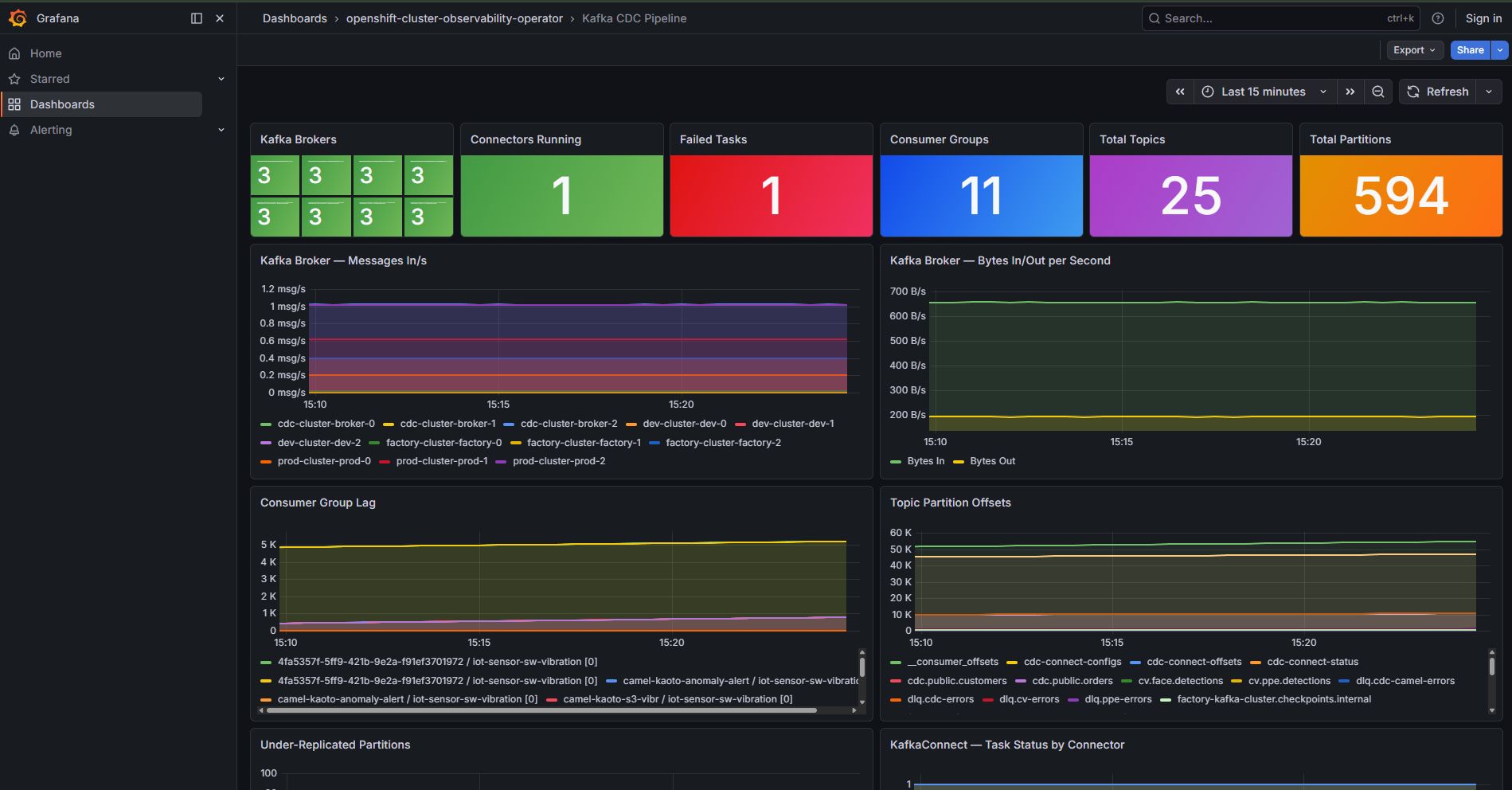
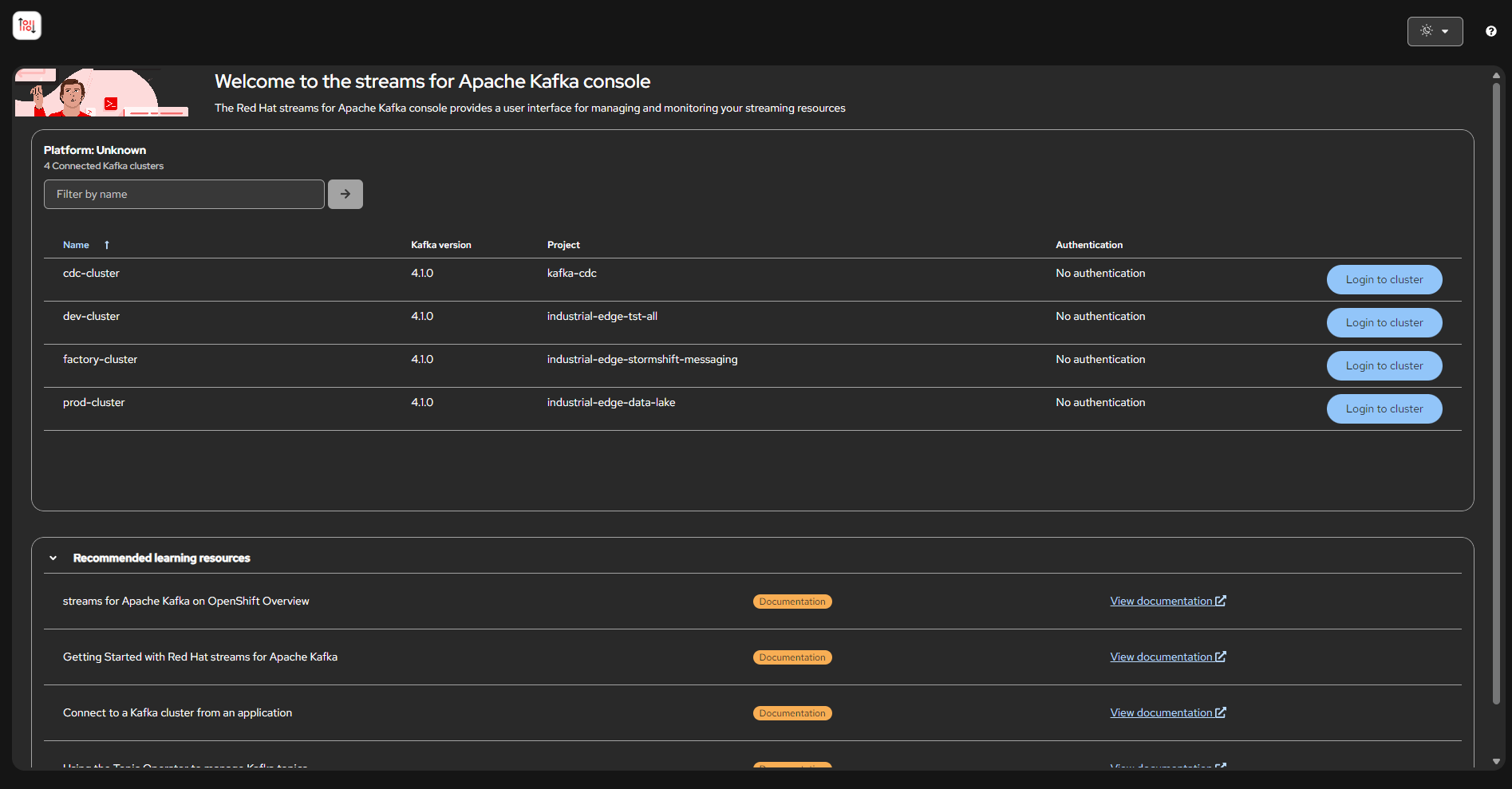
Explorar Kafka Streams — Inspecciona 3 clústeres Kafka, topics y mensajes en vivo
-
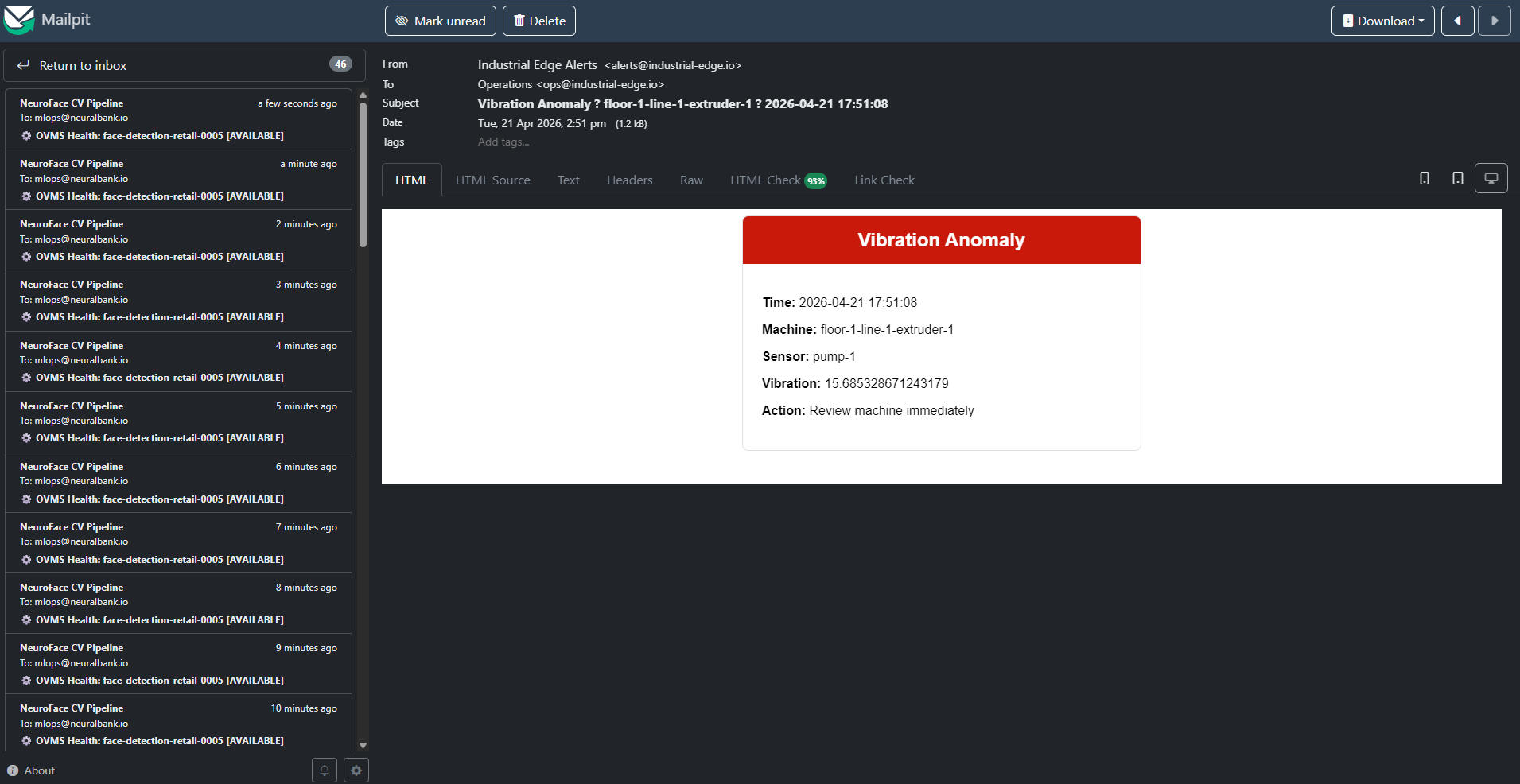
Line Dashboard y anomalías — Ve la detección de anomalías ML en vivo
-
Cambio de configuración GitOps — Habilita sensores de temperatura mediante ConfigMap
-
Data lake MinIO — Navega por los datos de sensores almacenados en S3