Event-Driven Architecture & Industrial Edge
Event-Driven Architecture & Industrial Edge
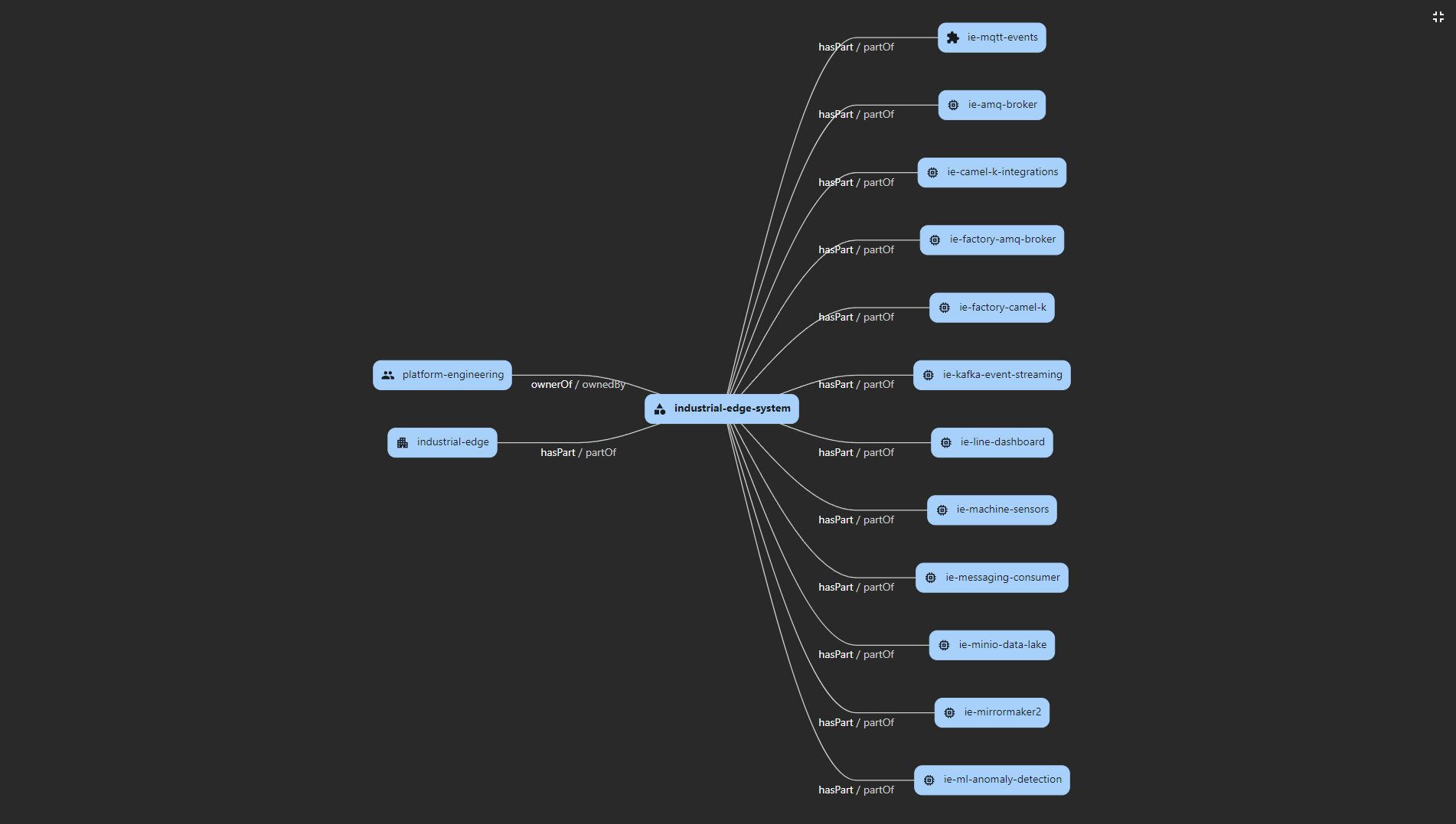
Industrial Edge Pattern
Use Case: Boosting manufacturing efficiency and product quality with artificial intelligence/machine learning (AI/ML) out to the edge of the network.
| Validation status | Based on | Links |
|---|---|---|
Background
Microcontrollers and other simple computers have long been used in factories and processing plants to monitor and control machinery in modern manufacturing. The industry has consistently leveraged technology to drive innovation, optimize production, and improve operations.
Supervisory Control and Data Acquisition (SCADA) systems have historically functioned independently of a company’s IT infrastructure. However, businesses increasingly recognize the value of integrating operational technology (OT) with IT. This integration enhances factory system flexibility and enables the adoption of advanced technologies such as AI and machine learning. As a result, tasks like maintenance can be scheduled based on real-time data rather than rigid schedules, while computing power is brought closer to the source of data generation.
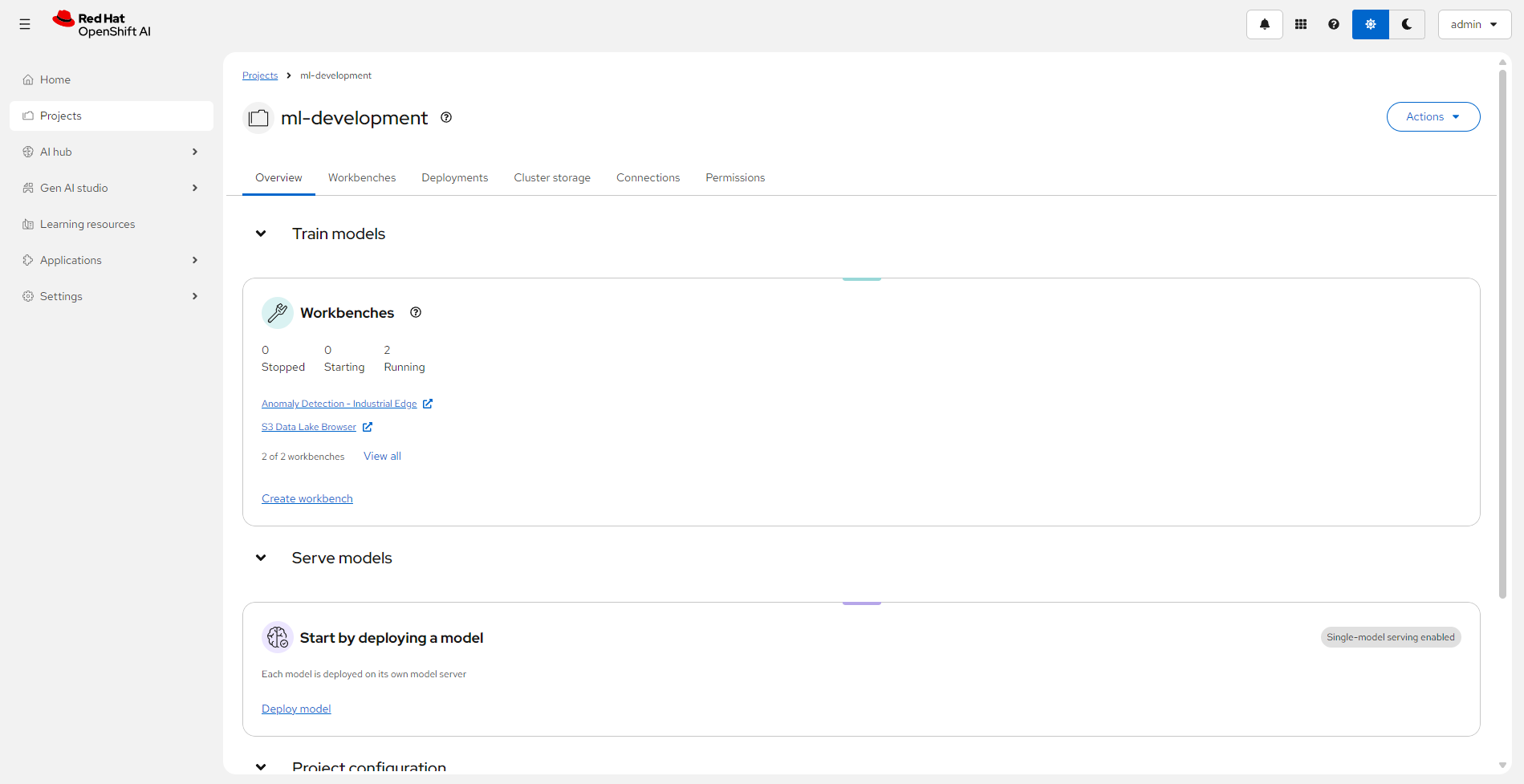
Solution Overview
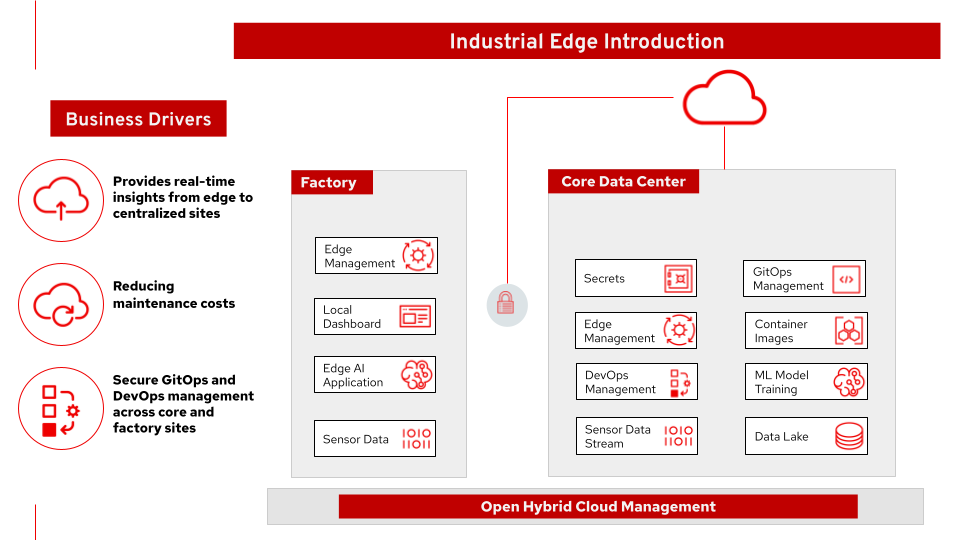
Figure 1. Industrial edge solution overview. It is applicable across a number of verticals including manufacturing.
This solution:
-
Provides real-time insights from the edge to the core datacenter
-
Secures GitOps and DevOps management across core and factory sites
-
Provides AI/ML tools that can reduce maintenance costs
-
Enables Change Data Capture (CDC) for real-time data synchronization
-
Offers Mirror/Replicas for external queries without impacting production
Different roles within an organization have different concerns and areas of focus when working with this distributed AI/ML architecture across two logical types of sites:
-
The core datacenter. This is where data scientists, developers, and operations personnel apply the changes to their models, application code, and configurations.
-
The factories. This is where new applications, updates and operational changes are deployed to improve quality and efficiency in the factory.
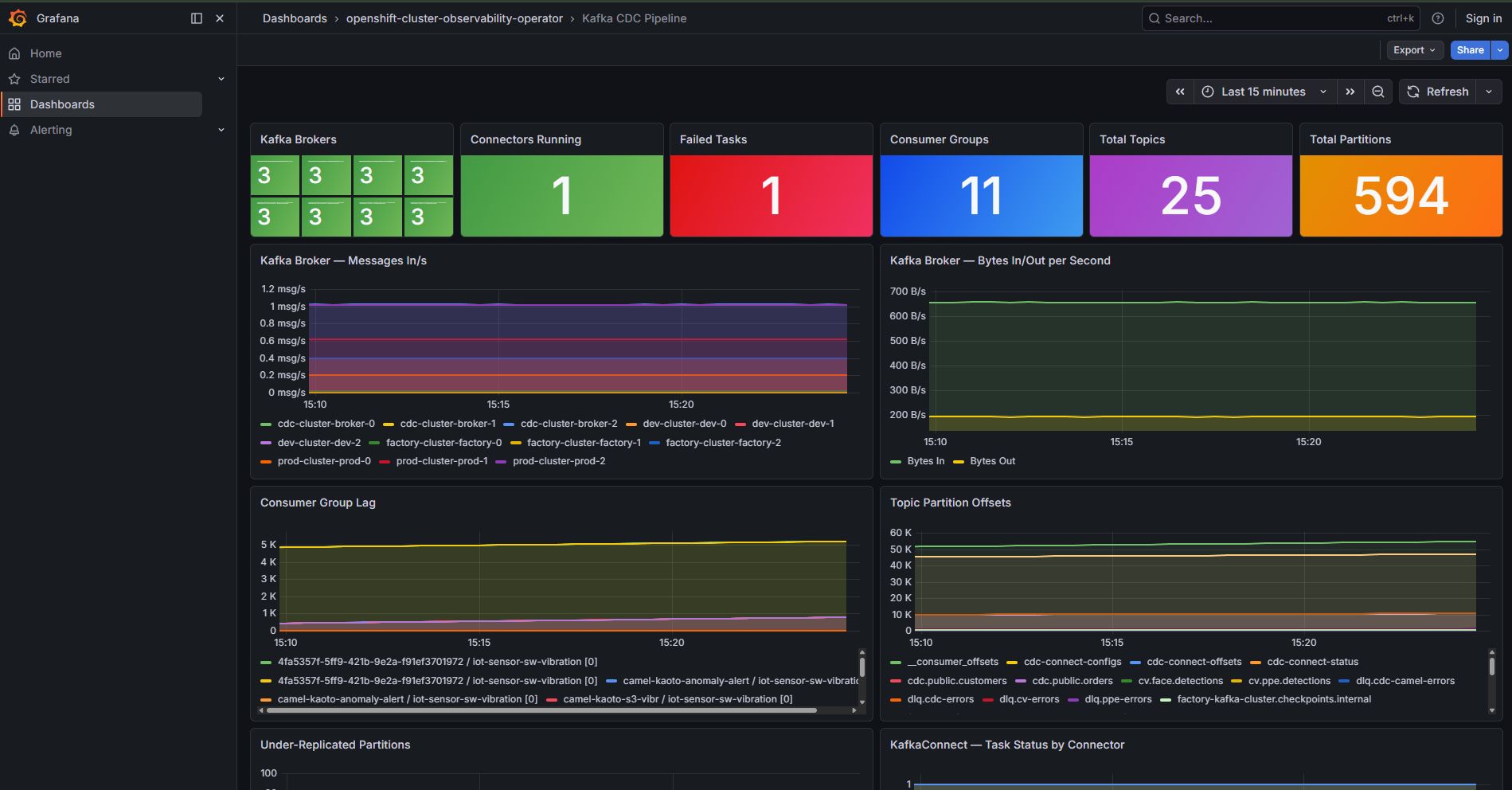
Logical Diagrams
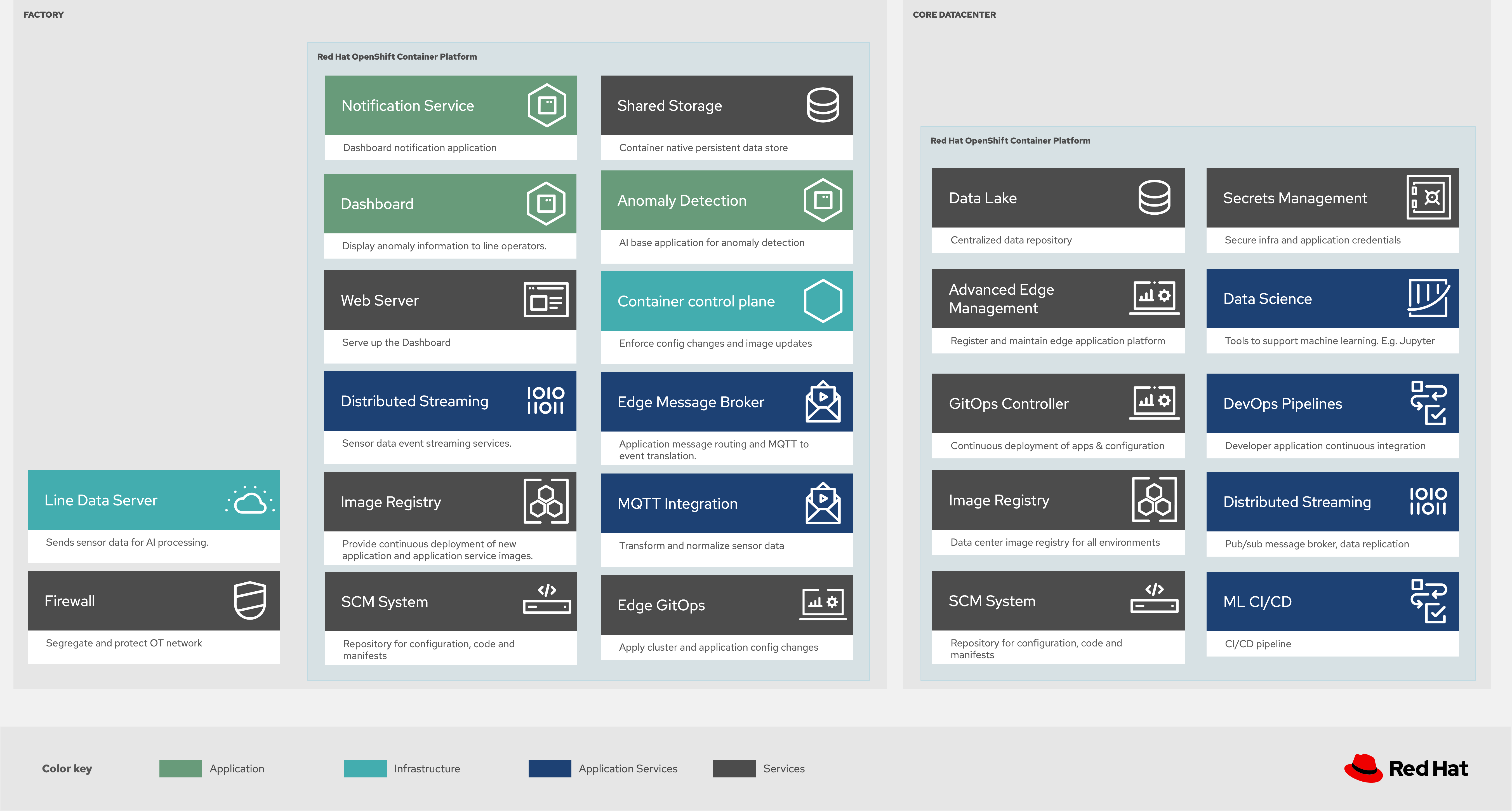
Figure 2. Industrial Edge solution as logically and physically distributed across multiple sites.
Overall Data Flows

Figure 3. Overall data flows of the solution.
Two major data flow streams:
-
Northbound (edge → core): Sensor data and events flow from the operational edge to the core for centralized processing. High volumes (tens of thousands of events per second) may make cloud transfer impractical.
-
Southbound (core → edge): Code, configurations, master data, and ML models are pushed from the core to the edge. With potentially hundreds of plants and thousands of production lines, automation and consistency are essential.
The Technology
| Technology | Description |
|---|---|
Enterprise-ready Kubernetes container platform built for an open hybrid cloud strategy. Provides a consistent application platform to manage hybrid cloud, public cloud, and edge deployments. |
|
Frameworks and capabilities for designing, building, deploying, connecting, securing, and scaling cloud-native applications. Includes Apache Camel, AMQ, and data streaming components. |
|
Massively scalable, distributed, and high-performance data streaming platform based on Apache Kafka. Offers a distributed backbone for microservices and IoT applications with high throughput and low latency. |
|
Flexible, scalable AI/ML platform that enables enterprises to create and deliver AI-enabled applications at scale across hybrid cloud environments. Includes JupyterLab, ModelMesh, and Data Science Pipelines. |
|
Controls clusters and applications from a single console, with built-in security policies. Deploys applications, manages multiple clusters, and enforces policies at scale. |
|
Self-service developer portal based on Backstage. Provides software templates, TechDocs, and integrated plugins for Kafka, Topology, and CI/CD. |
|
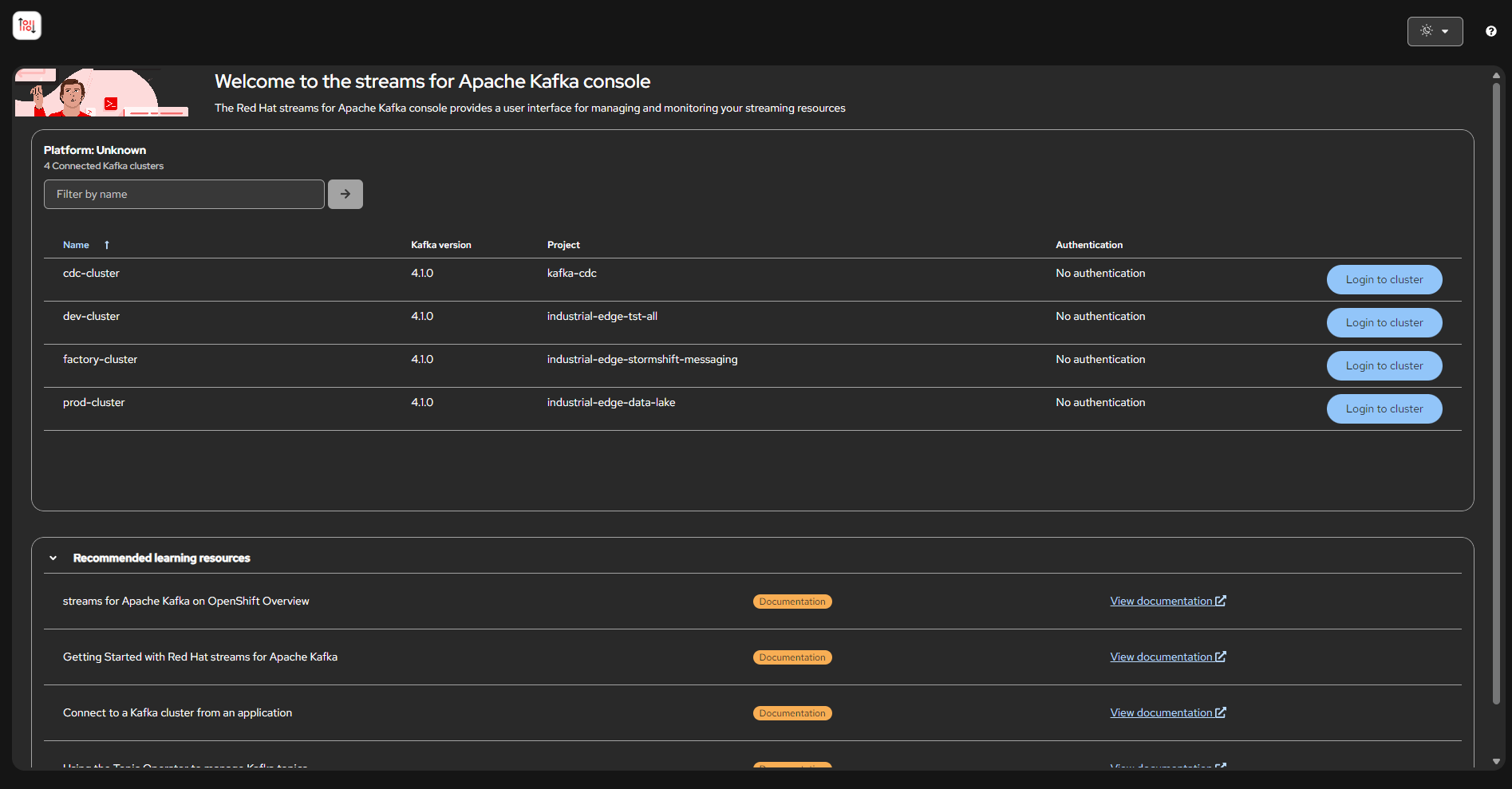
Kubernetes operator for Apache Kafka. Manages Kafka clusters, topics, users, MirrorMaker2, and KafkaConnect in a declarative way using Custom Resources. |
|
Open-source CDC platform. Captures row-level changes from databases (PostgreSQL, MySQL, SQL Server) and publishes them as events to Kafka. |
Architectures
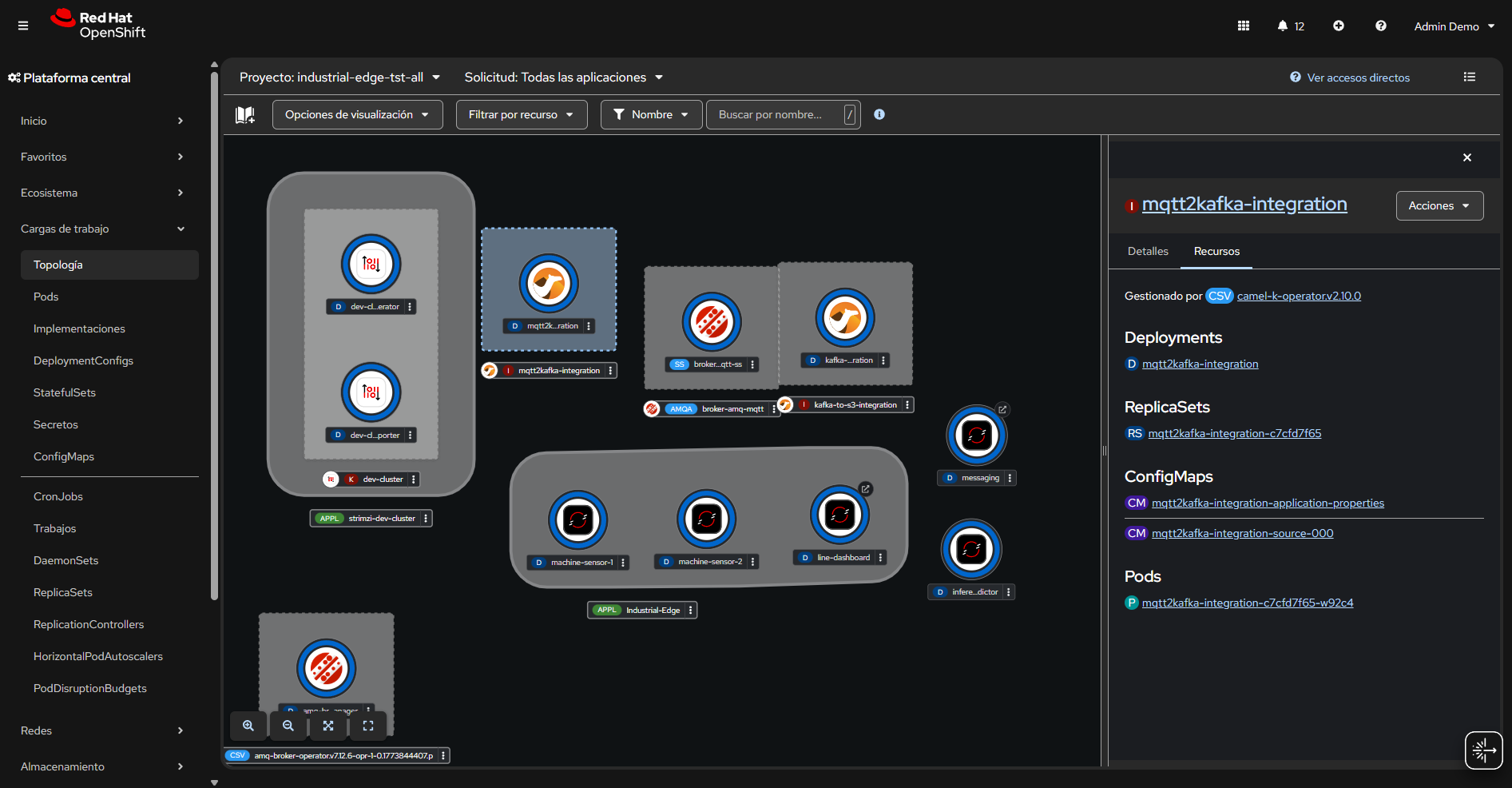
Edge Manufacturing with Messaging and ML
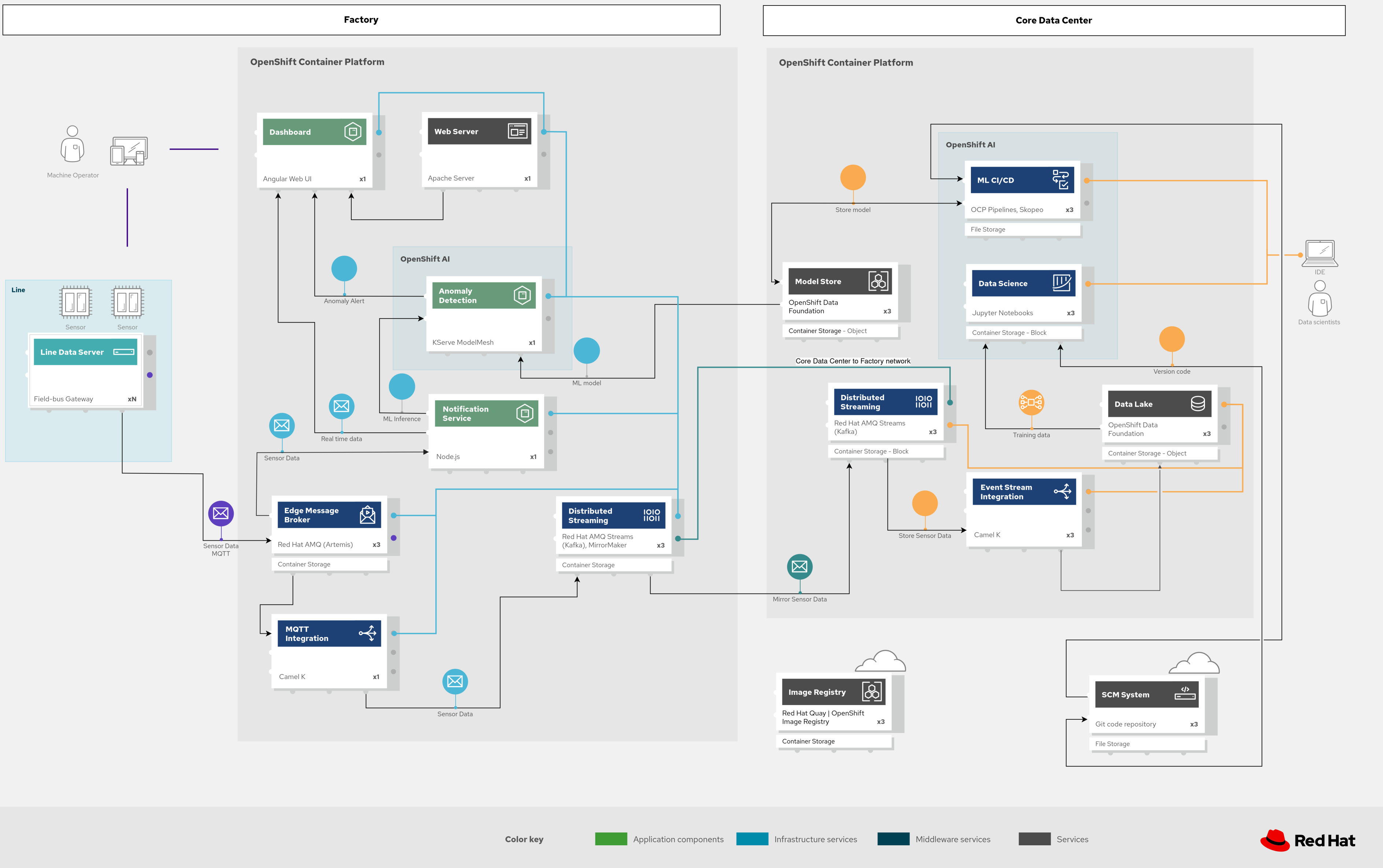
Figure 4. Industrial Edge solution showing messaging and ML components schematically.
Sensor data is transmitted via MQTT to Red Hat AMQ, which routes it for two purposes:
-
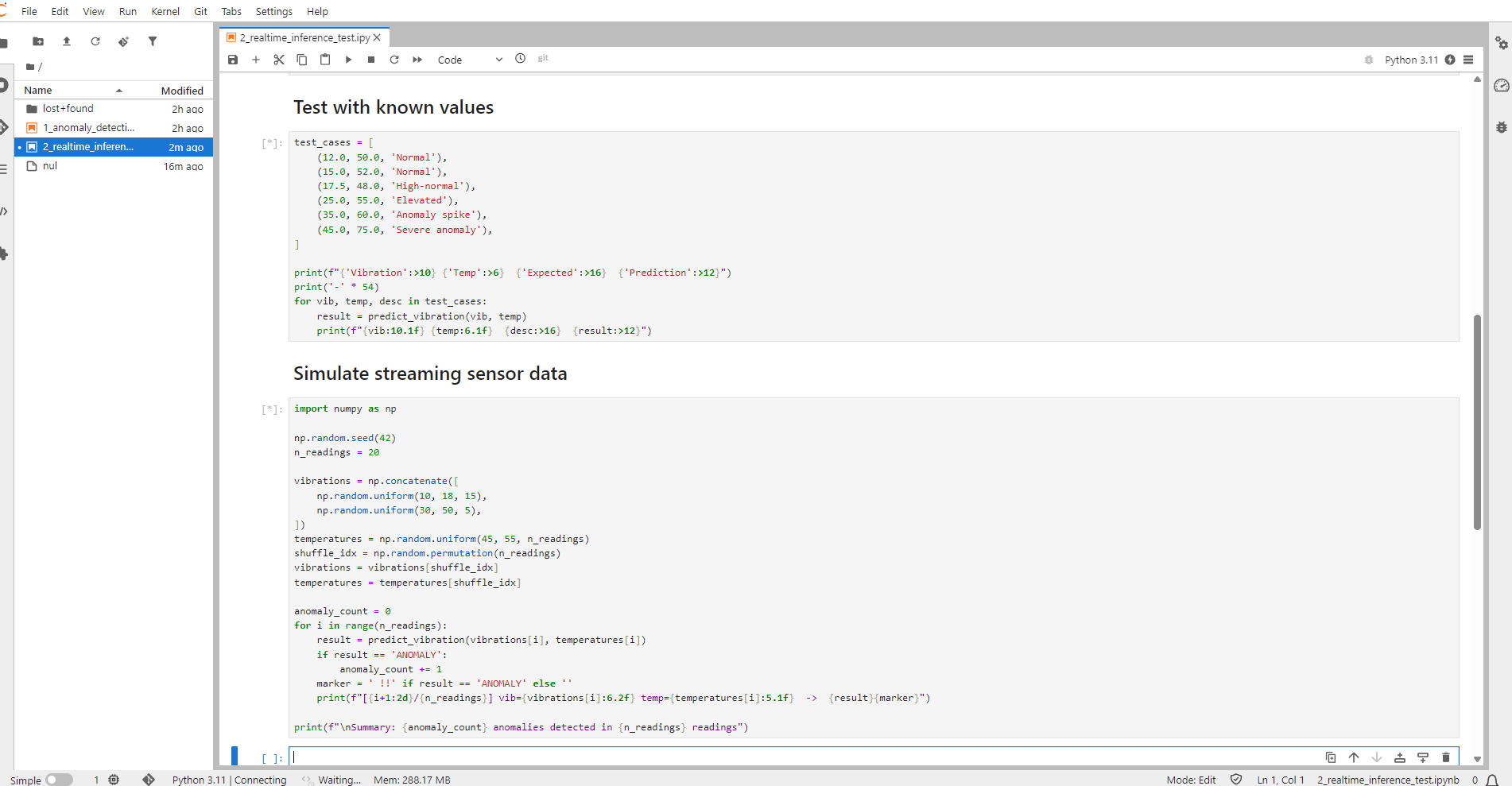
Model development in the core data center (data lake → JupyterLab → training)
-
Live inference at the factory data centers (IoT Consumer → ModelMesh → anomaly alerts)
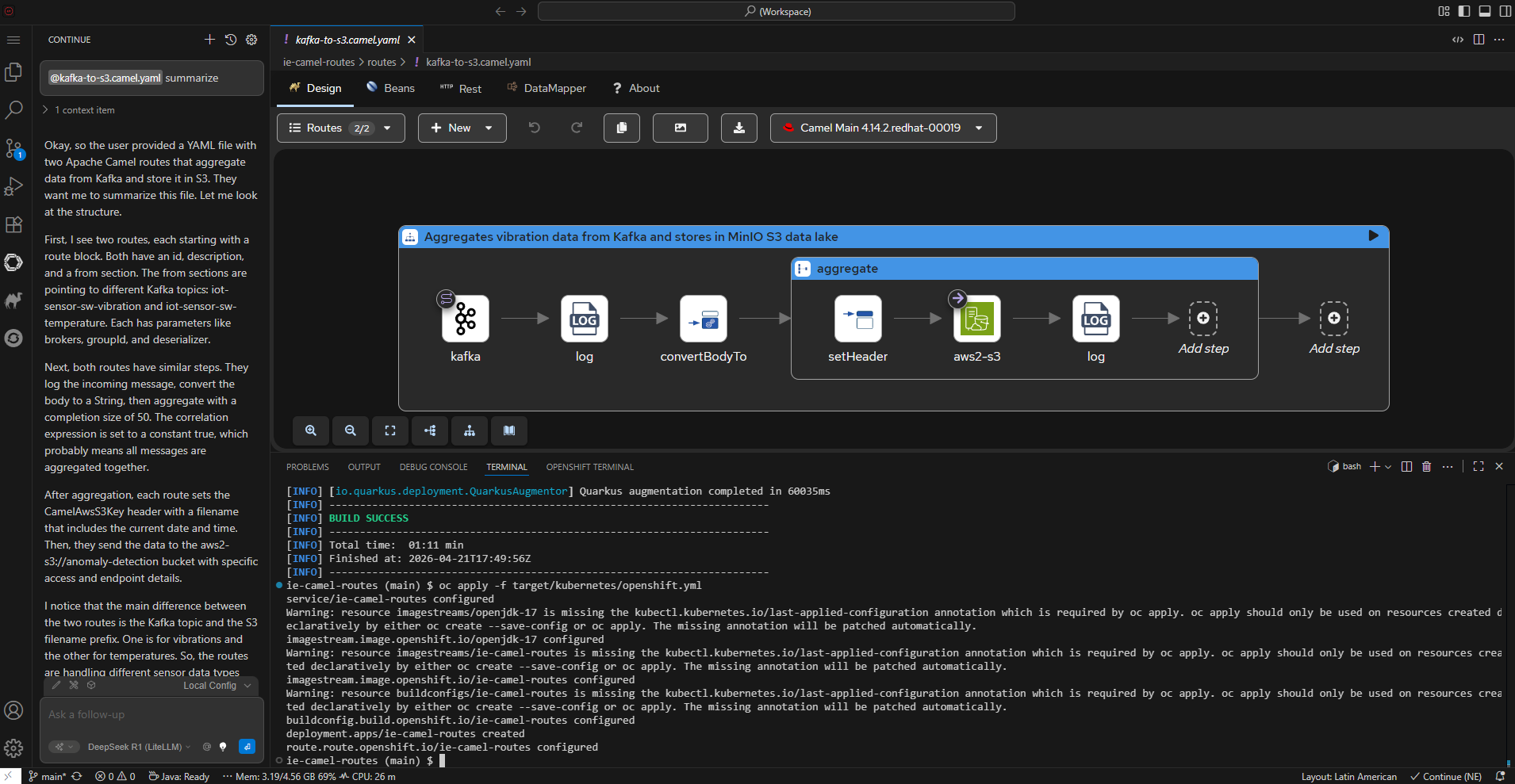
Apache Camel K provides MQTT integration to normalize and route sensor data to Kafka and then to S3 (MinIO) for the data lake. Data scientists use OpenShift AI tools to develop, train, and deploy models.
Edge Manufacturing with GitOps
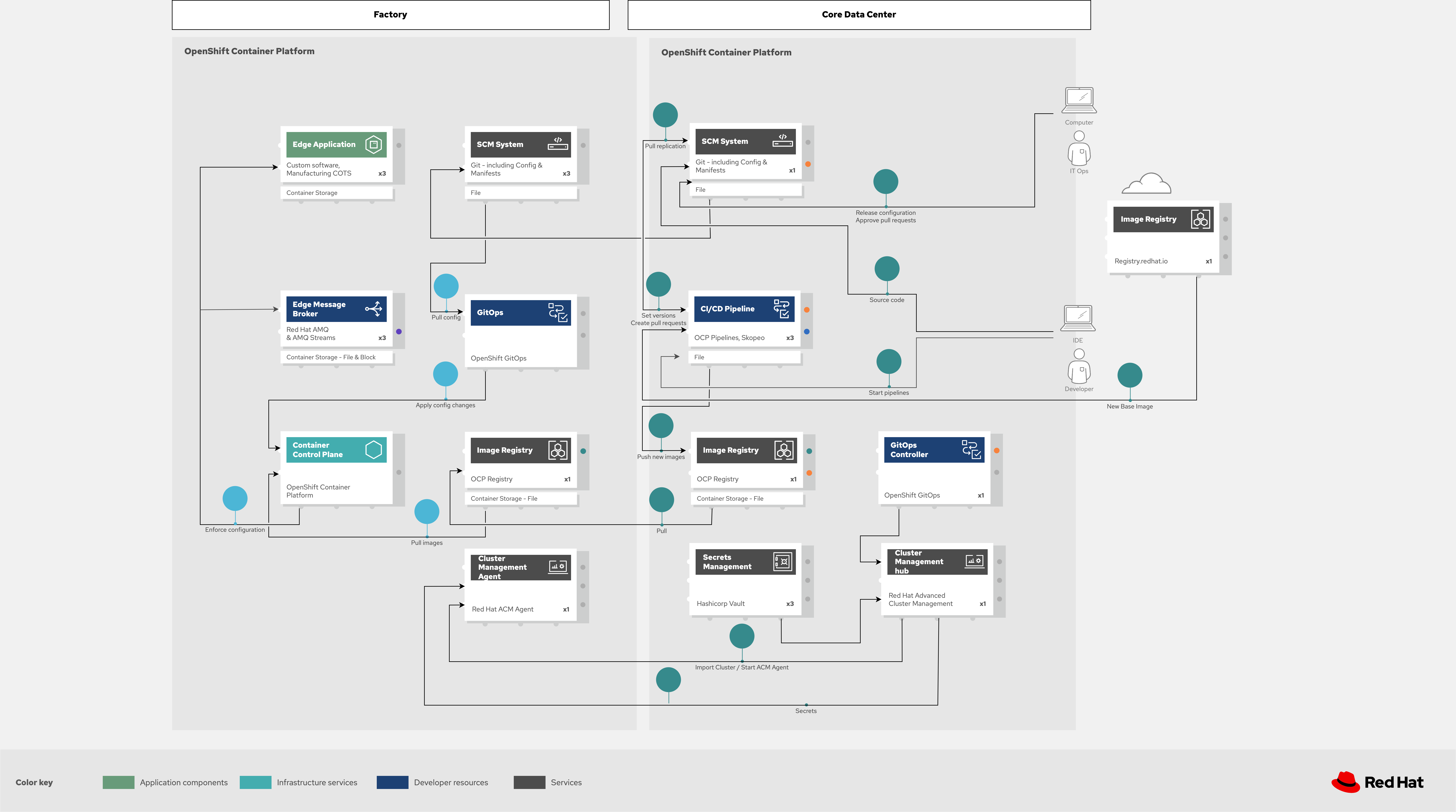
Figure 5. Industrial Edge solution showing a schematic view of the GitOps workflows.
GitOps provides a consistent, declarative approach to managing cluster changes and upgrades across centralized and edge sites. Changes to configuration and applications are automatically pushed into operational systems at the factory via ArgoCD.
Change Data Capture (CDC)
CDC with Debezium captures changes from relational databases and publishes them as events to a dedicated Kafka cluster. This enables:
-
Event sourcing and view materialization
-
Microservice synchronization
-
Real-time auditing and compliance
-
Analytics and search indexing
At 20K device scale, the CDC component handles ~5,000 DB transactions/sec with 5 consumer groups (Camel K, notifications, search indexer, analytics, audit logger).
Mirror/Replicas for External Queries
KafkaMirrorMaker2 replicates CDC and IoT topics to a read-only mirror cluster for external access:
-
Analytics/BI consumers reading data without affecting production latency
-
Geographic replication for teams in other regions
-
Disaster recovery cluster with up-to-date data
-
Secure external access (TLS + SCRAM-SHA-512) without exposing internal clusters
At 20K scale, the mirror handles 13K msg/sec from 3 source clusters with 7 external consumer groups.
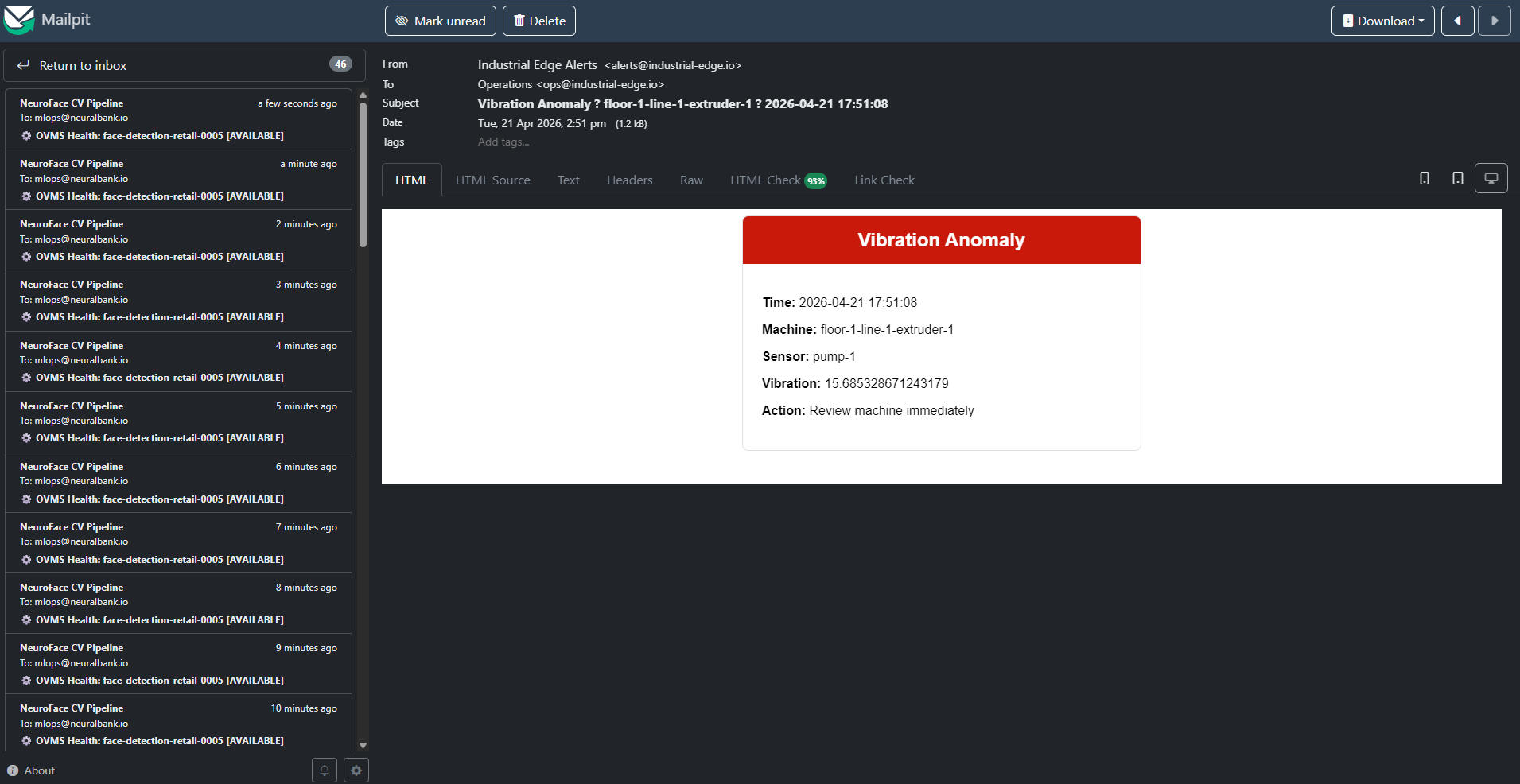
Demo Scenario
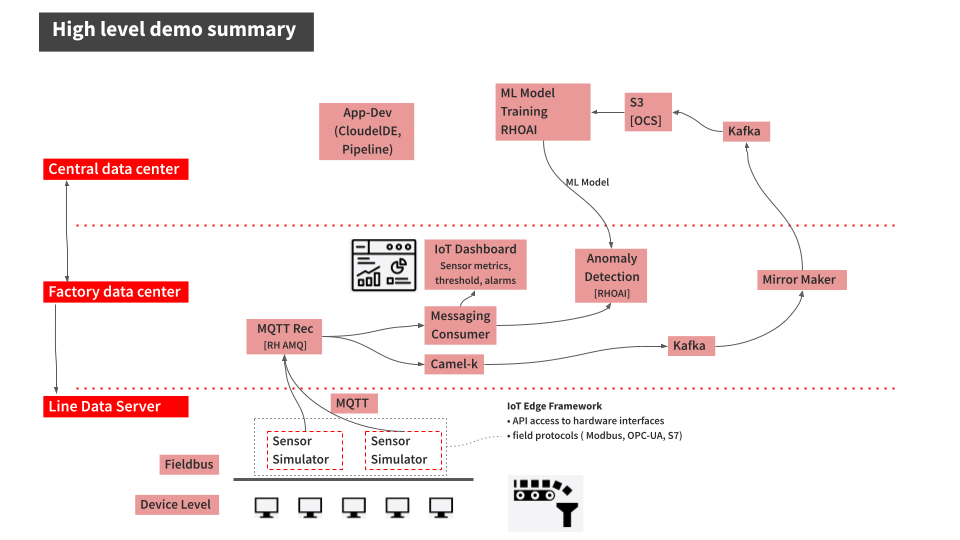
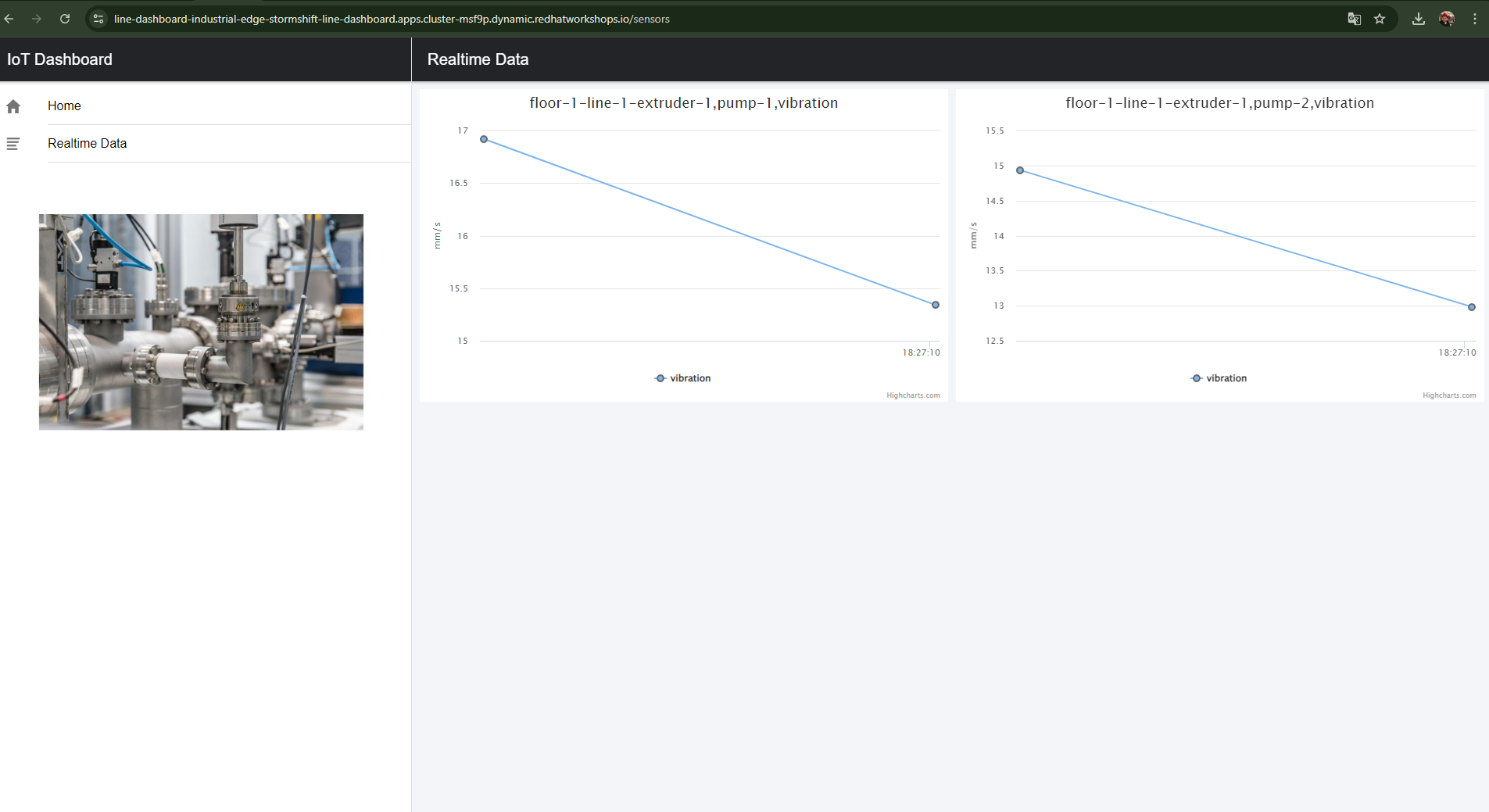
Figure 6. High-level demo summary showing machine condition monitoring based on sensor data.
The demo scenario has three layers:
-
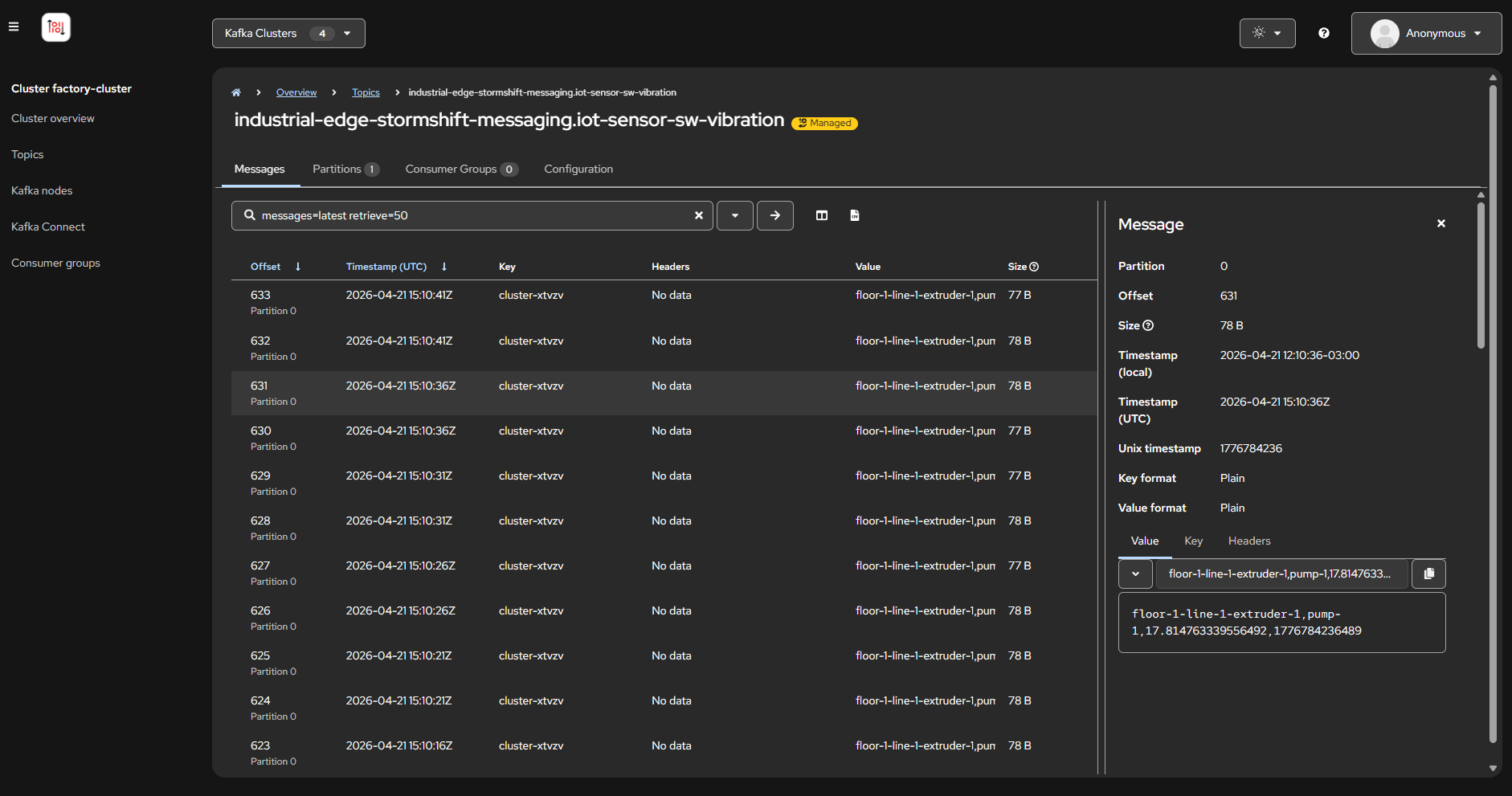
Line Data Server (far edge): Machine sensors on the shop floor publishing vibration and temperature readings via MQTT every 5 seconds.
-
Factory Data Center (near edge): AMQ Broker receives MQTT data. Camel K bridges MQTT→Kafka. Factory Kafka streams data. IoT Consumer feeds ModelMesh for anomaly detection. Line Dashboard provides real-time visualization.
-
Central Data Center (core): Kafka data lake stores mirrored data. Camel K integration writes to MinIO S3. OpenShift AI provides JupyterLab notebooks, Data Science Pipelines, and ModelMesh serving.
What’s Running
| Component | What it does | Namespace |
|---|---|---|
Machine Sensors (x4) |
Simulate vibration and temperature readings every 5 seconds via MQTT |
|
AMQ Broker (x2) |
MQTT broker receiving sensor data at the factory edge |
|
Kafka Clusters (x3) |
Dev, Factory, and Data Lake clusters for event streaming |
|
Camel K |
MQTT→Kafka bridge and Kafka→S3 data lake integration |
|
Line Dashboard (x2) |
Real-time visualization of sensor data and anomaly alerts |
|
MinIO S3 |
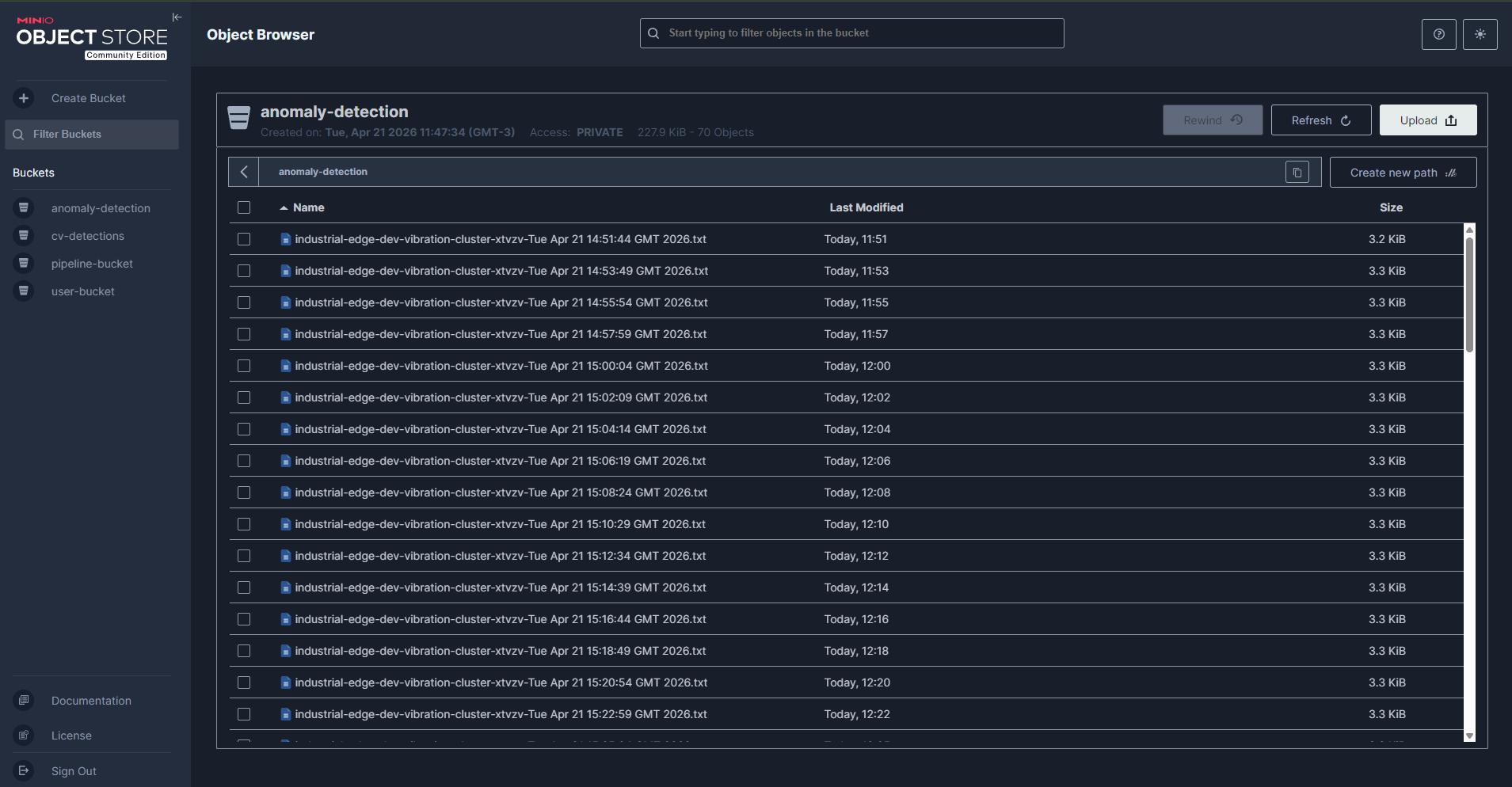
Object storage for the data lake (model training data, artifacts) |
|
OpenShift AI |
JupyterLab + ModelMesh + Data Science Pipelines |
|
IoT Consumer (messaging) |
Backend that consumes MQTT sensor data and forwards to ML inference |
|
Demo Script
To explore the Industrial Edge deployment, follow the showroom guide:
-
Observe IoT Sensors — Watch sensor data flow in real-time
-
Explore Kafka Streams — Inspect 3 Kafka clusters, topics, and live messages
-
Line Dashboard & Anomalies — See ML anomaly detection live
-
GitOps Config Change — Enable temperature sensors via ConfigMap
-
MinIO Data Lake — Browse stored sensor data in S3