Architecture
v2.2+ default deploy: AI Computer Vision at the Edge —
spoke-neuroface+spoke-neuroface-cvon east/west, hubneuroface-gateway(50/50). Industrial Edge (MQTT, line-dashboard, sensors) is optional and disabled by default; enable by uncommenting IE apps in region values.
Hub-spoke theory in multi-cluster Kubernetes
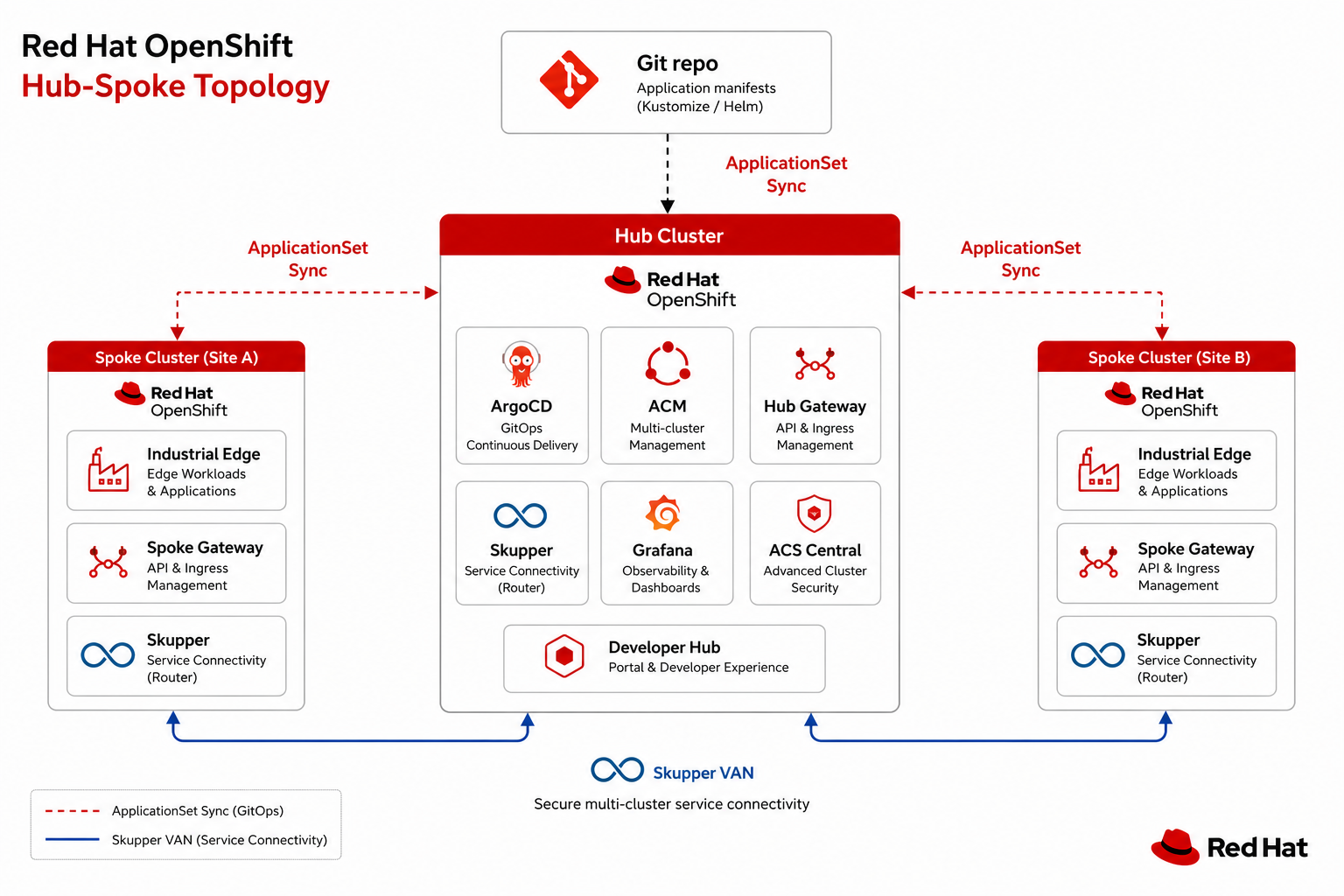
In multi-cluster Kubernetes, a hub-spoke model designates one administrative cluster (the hub) and one or more workload clusters (spokes). The hub owns fleet APIs: cluster inventory, policy placement, credentials for spoke registration, and often centralized GitOps controllers that fan out desired state.
Spokes remain the execution venues for application namespaces, data-plane components (Kafka, MQTT bridges, mesh dataplane), and regional isolation for latency, data residency, or blast-radius control.
Why hub-spoke?
| Benefit | Description |
|---|---|
| Centralized management | One control plane for membership, RBAC patterns, and bulk upgrades. |
| Policy enforcement | Kubernetes policies, compliance checks, and security baselines propagate from the hub. |
| Observability | Aggregated metrics, logging, and tracing strategies start at the hub and uniform dashboards span spokes. |
| GitOps consistency | A single Git revision (main) with region paths drives spoke drift correction. |
Platform architecture overview
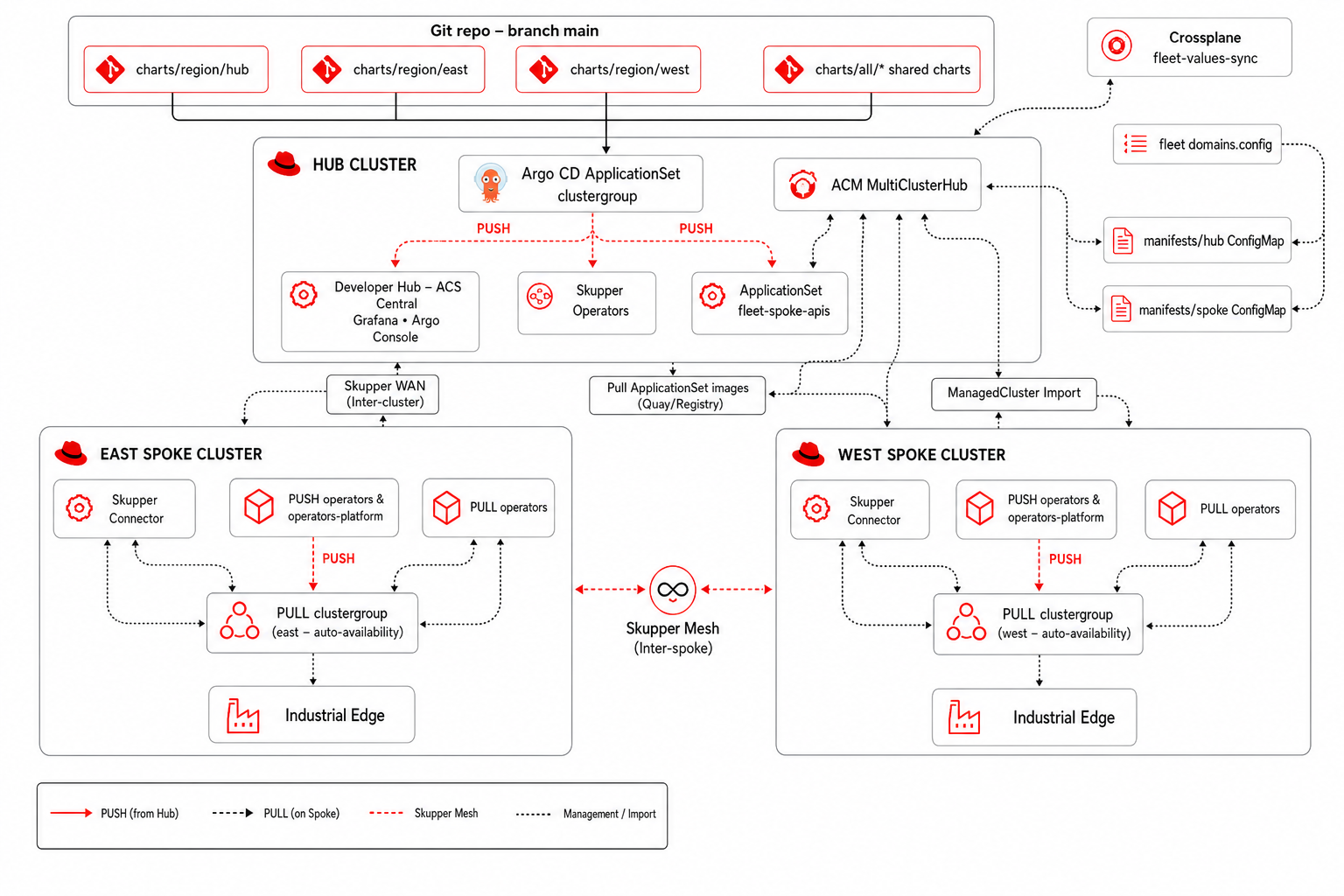
Single main branch: hub at charts/region/hub, spokes at charts/region/east and charts/region/west, shared charts under charts/all/. CronJob fleet-values-sync patches cross-cluster domains — see fleet-values-sync.
Single main branch: hub at charts/region/hub, spokes at charts/region/east and charts/region/west, shared charts under charts/all/.
Follow the request — one temperature reading end to end
When a machine sensor on the east spoke publishes a temperature sample, the path is: MQTT (messaging broker) → Camel K (mqtt-to-kafka integration) → Kafka (dev-cluster topic) → optional ML scoring (KServe) → line-dashboard WebSocket consumer. In parallel, Thanos Querier on east scrapes Istio and Kafka metrics; a Skupper Connector (prometheus-east) tunnels HTTP to the hub, where Grafana datasource prometheus-east plots the series. The Hub Gateway can route browser traffic to the east line-dashboard via spoke-gateway and Skupper listener ie-gateway-east. Developer Hub Topology shows the same pods when the catalog entity carries backstage.io/kubernetes-cluster: east and spoke API tokens are synced.
Components on the hub vs spokes
| Area | Hub | Spokes | Config path |
|---|---|---|---|
| ACM hub operator & APIs | yes | charts/region/hub/values.yaml | |
| ArgoCD / clustergroup root | yes | yes | charts/region/hub / charts/region/east / charts/region/west |
| ApplicationSet (spoke apps) | yes | charts/region/hub/values.yaml | |
| ACS Central | yes | charts/region/hub/values.yaml | |
| ACS Secured Cluster | yes | charts/region/east|west/values.yaml | |
| Developer Hub | yes | charts/region/hub/values.yaml | |
| Hub Gateway (Gateway API) | yes | charts/region/hub/values.yaml | |
| Spoke Gateway (Gateway API) | yes | charts/region/east|west/values.yaml | |
| Industrial Edge workloads | yes | charts/region/east|west/values.yaml | |
| Kafka brokers (regional) | yes | charts/region/east|west/values.yaml | |
| Service Mesh ambient / ztunnel | yes | yes | both |
Istio CNI (profile: ambient) | yes | yes | both |
| Skupper Site (hub listeners) | yes | charts/region/hub/values.yaml | |
| Skupper Site (spoke connectors) | yes | charts/region/east|west/values.yaml | |
| Grafana (multi-cluster dashboards) | yes | charts/region/hub/values.yaml | |
| Grafana (local metrics) | yes | charts/region/east|west/values.yaml | |
| Kiali + OSSM Console plugin | yes | yes | both |
| Connectivity Link (RHCL) | yes | yes | both |
| Kubecost (primary aggregator) | yes | charts/region/hub/values.yaml | |
| Kubecost (agent) | yes | charts/region/east|west/values.yaml | |
| Kafka Console (all clusters) | yes | charts/region/hub/values.yaml |
GitOps application delivery flow
See GitOps deployment chain for the full encadenamiento (hub field-content-* → ApplicationSet fleet-spoke-push → *-spoke-components → spoke *-east / *-west apps) with copy-paste YAML fragments.
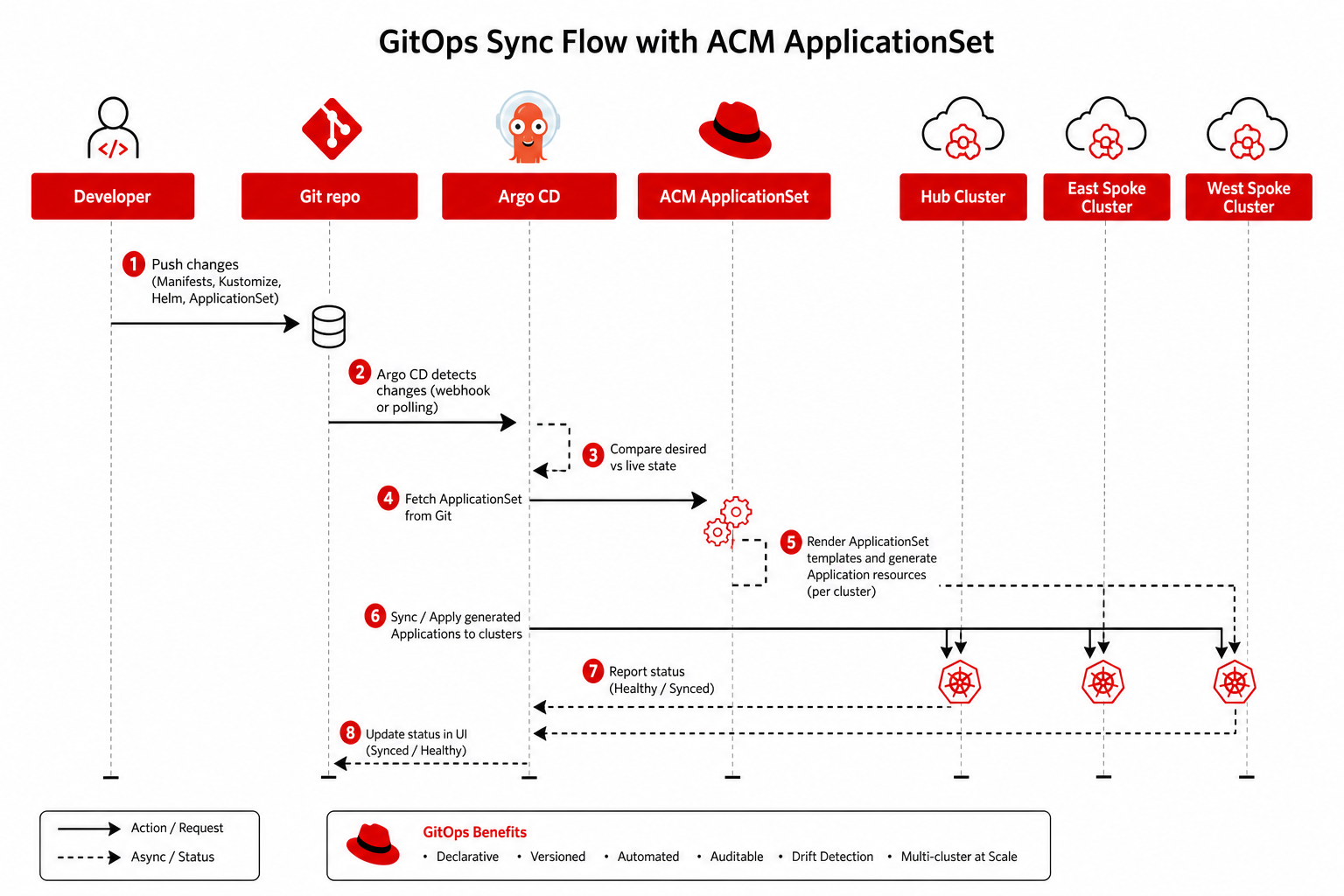
Hub syncs first; ApplicationSet pushes per-spoke charts; each spoke Argo CD reconciles child Applications locally.
Sync wave ordering
Components deploy in strict order via ArgoCD sync waves:
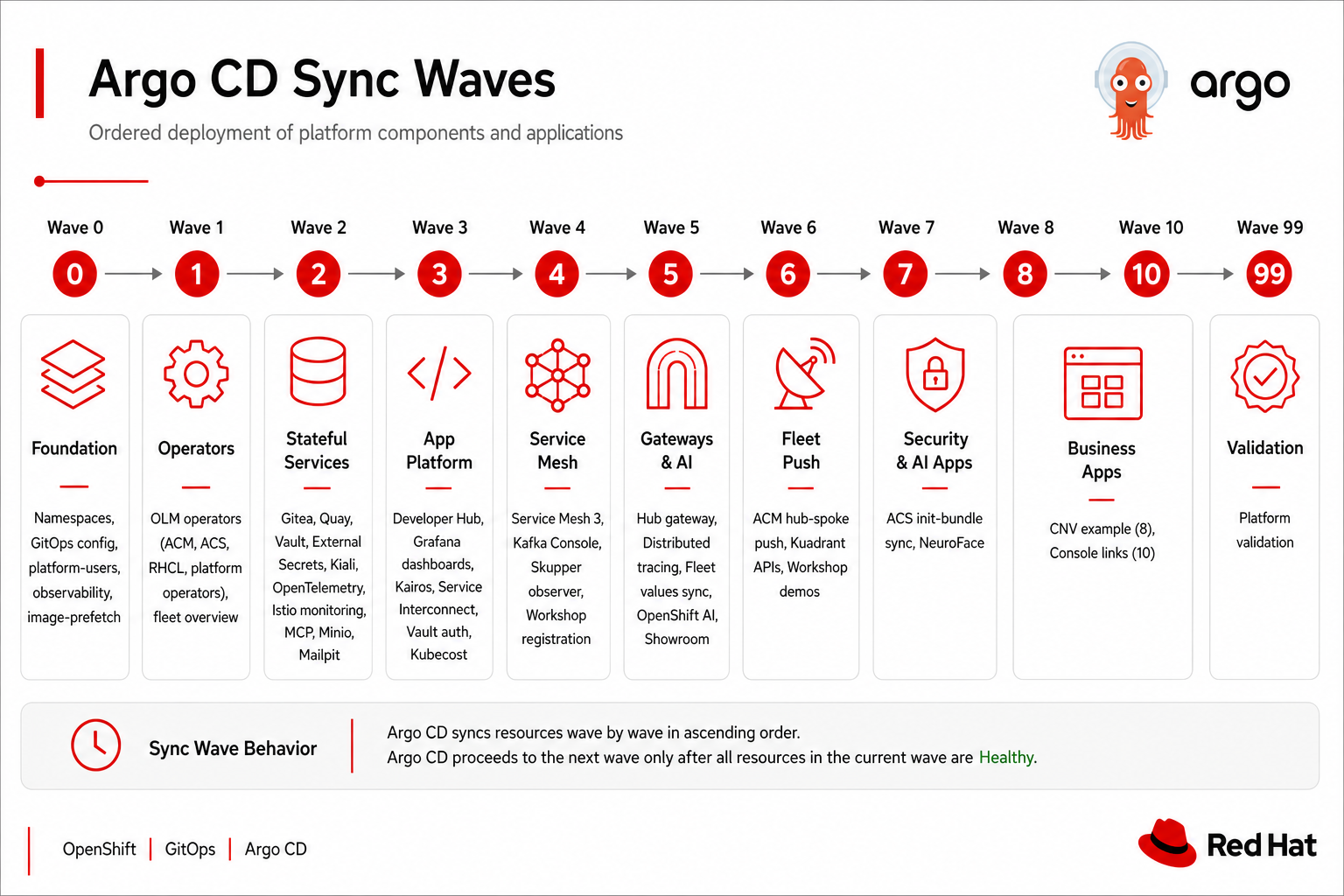
Sync waves prevent operators from racing workloads — mesh and namespaces land before Industrial Edge and gateways.
Spoke sync-wave reference
Matches ebook Ch.4 ordering (charts/region/east/values.yaml, charts/region/west/values.yaml):
| Wave | What deploys | Why this order |
|---|---|---|
| 1 | Namespaces (no ambient label yet) | Names must exist before operators and workloads |
| 2 | OLM Subscriptions | CRDs and operators installed |
| 3 | Service Mesh 3 (Istio + ZTunnel + ambient labels wave 2 inside chart) | Mesh dataplane before application pods |
| 4 | Observability, ACS secured cluster | Scraping and security after mesh |
| 5 | Industrial Edge (Kafka, sensors, dashboard) | Pods enroll in ambient with HBONE ready |
| 6 | Spoke gateway + Skupper interconnect | Routing after backends exist |
Hub chart uses a similar pattern; ApplicationSet for spokes runs at hub wave 5 after ACM placement is healthy.
Service Interconnect (Skupper) topology
Red Hat Service Interconnect creates a Virtual Application Network (VAN) that bridges services across clusters without VPN or direct network connectivity.
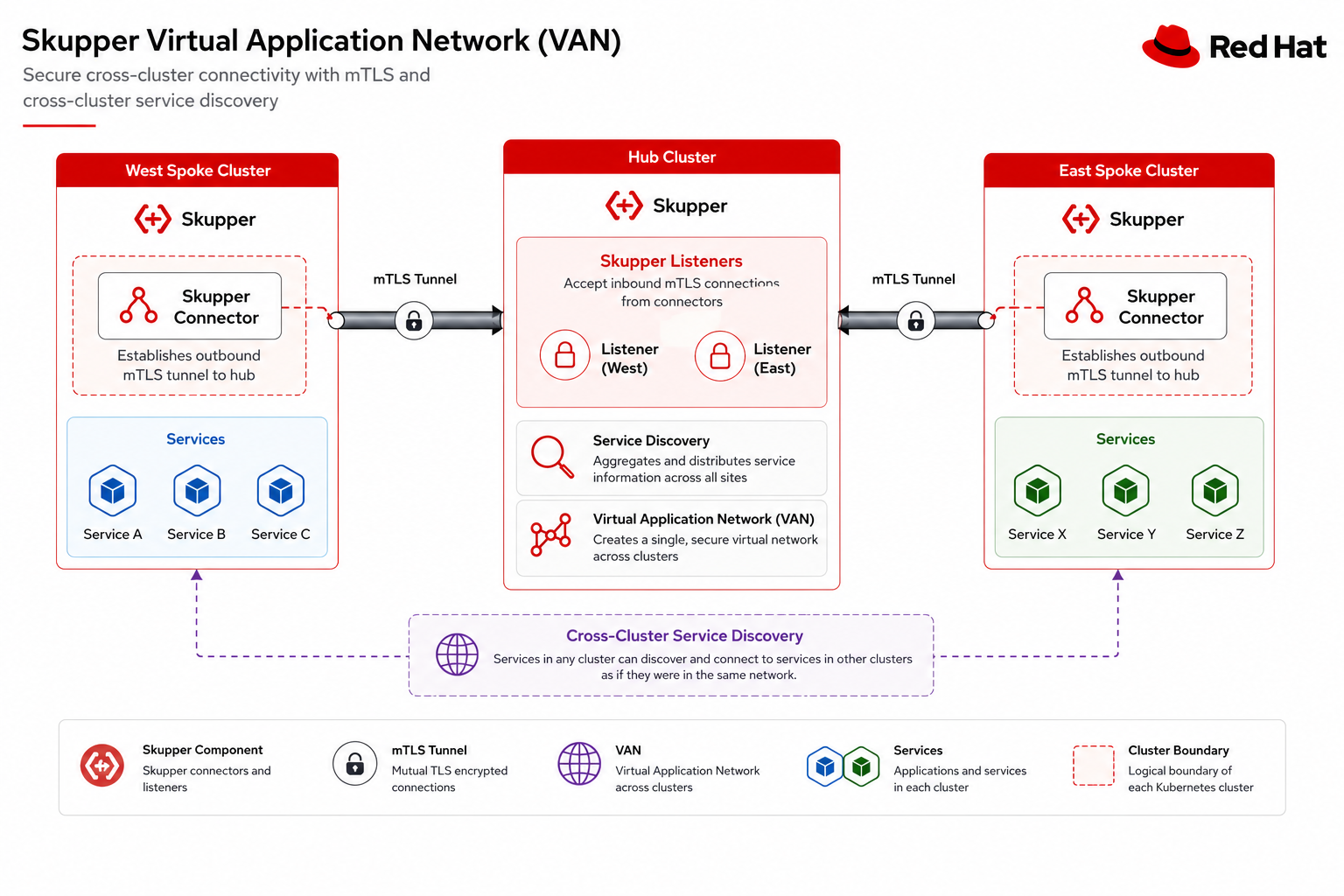
Connectors expose spoke-gateway and prometheus-auth-proxy; Listeners materialize ClusterIP services on the hub.
Spoke gateway aggregation
Each spoke runs a Gateway API gateway that fronts all Industrial Edge services, providing a single entry point for Skupper to expose to the hub.
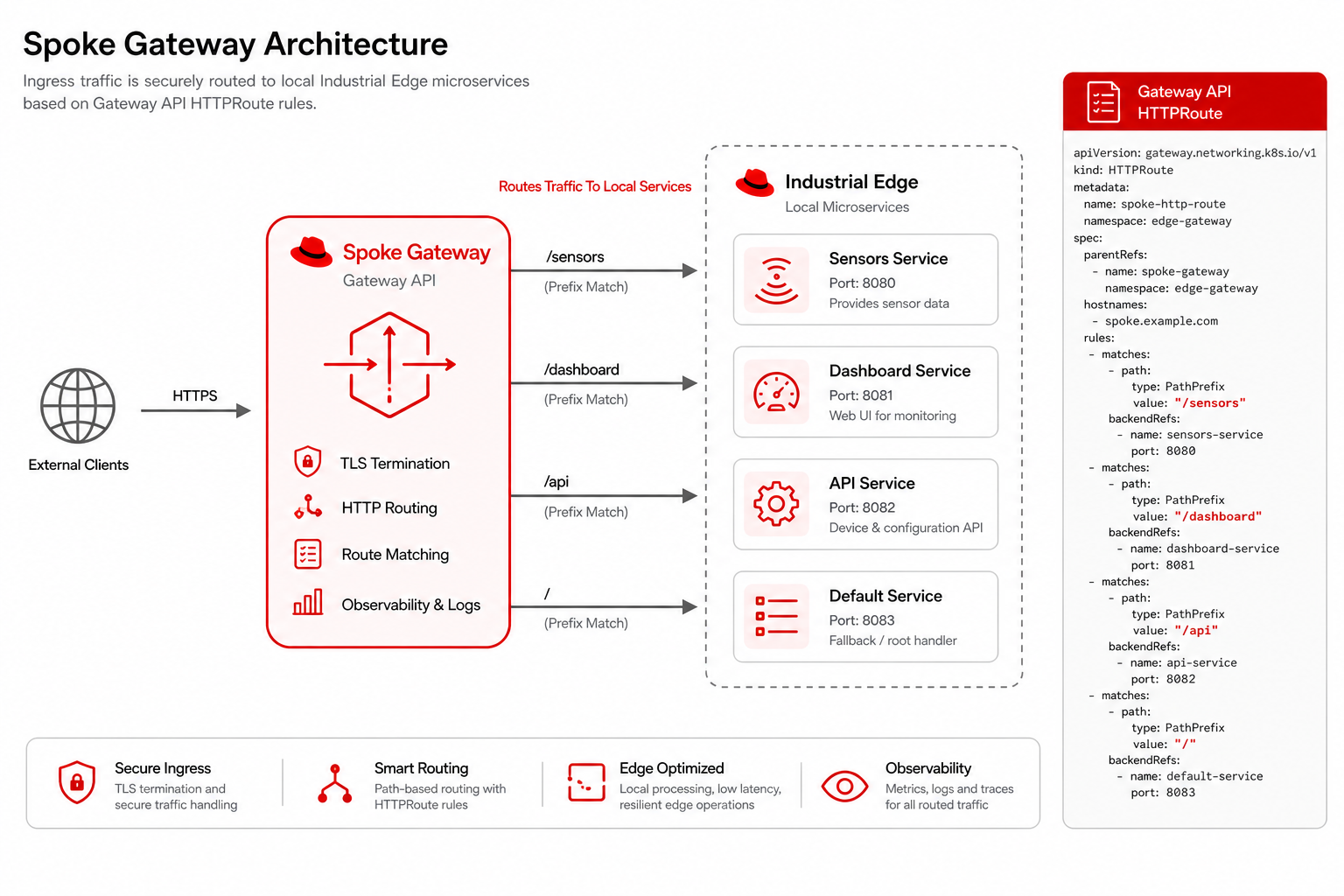
One Connector per spoke exposes the gateway instead of every microservice individually.
Multi-cluster observability pipeline
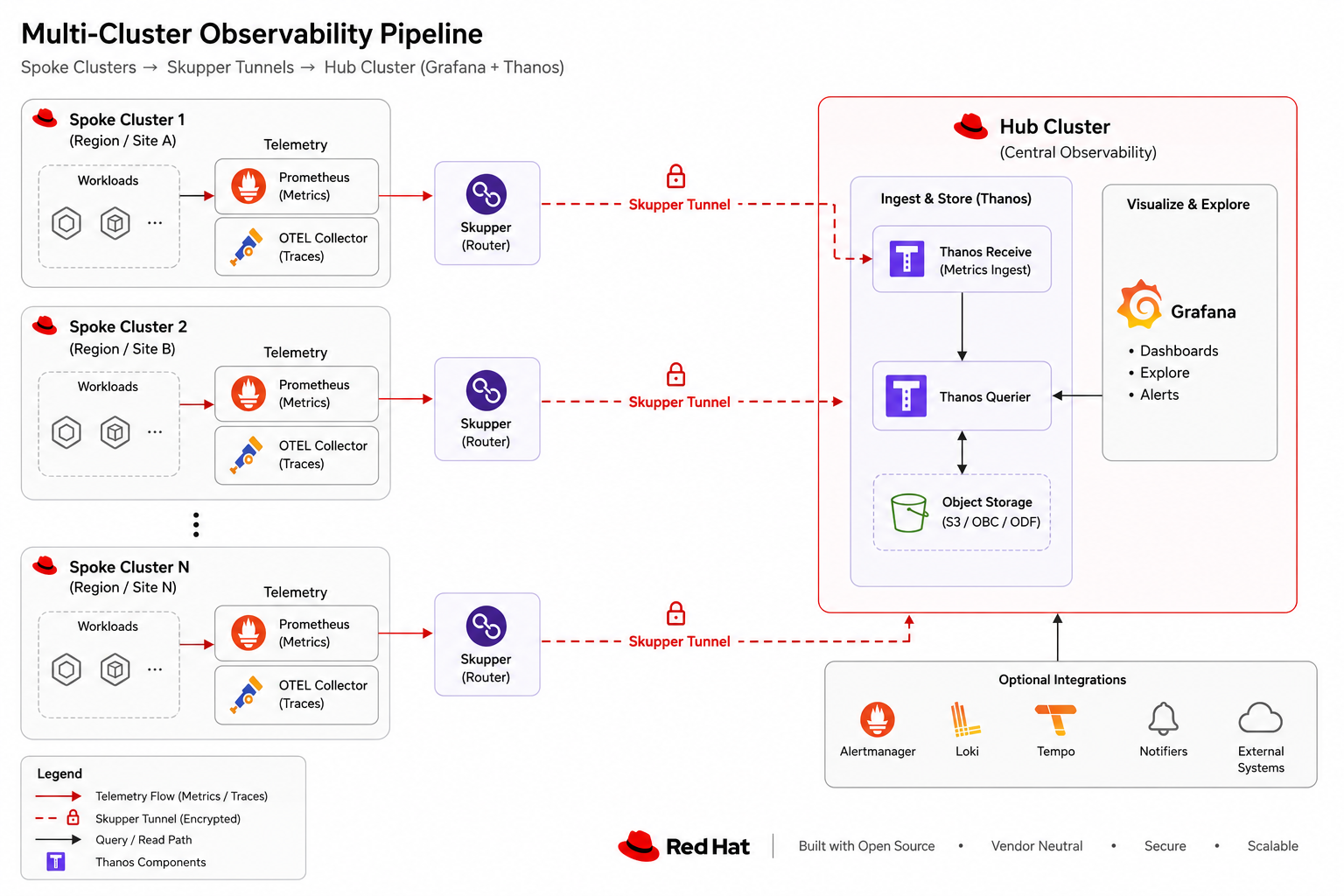
Spoke Thanos Querier is reached through nginx auth-proxy Connectors; hub Grafana uses HTTP datasources without bearer tokens.
Data flow (sensors to dashboard)
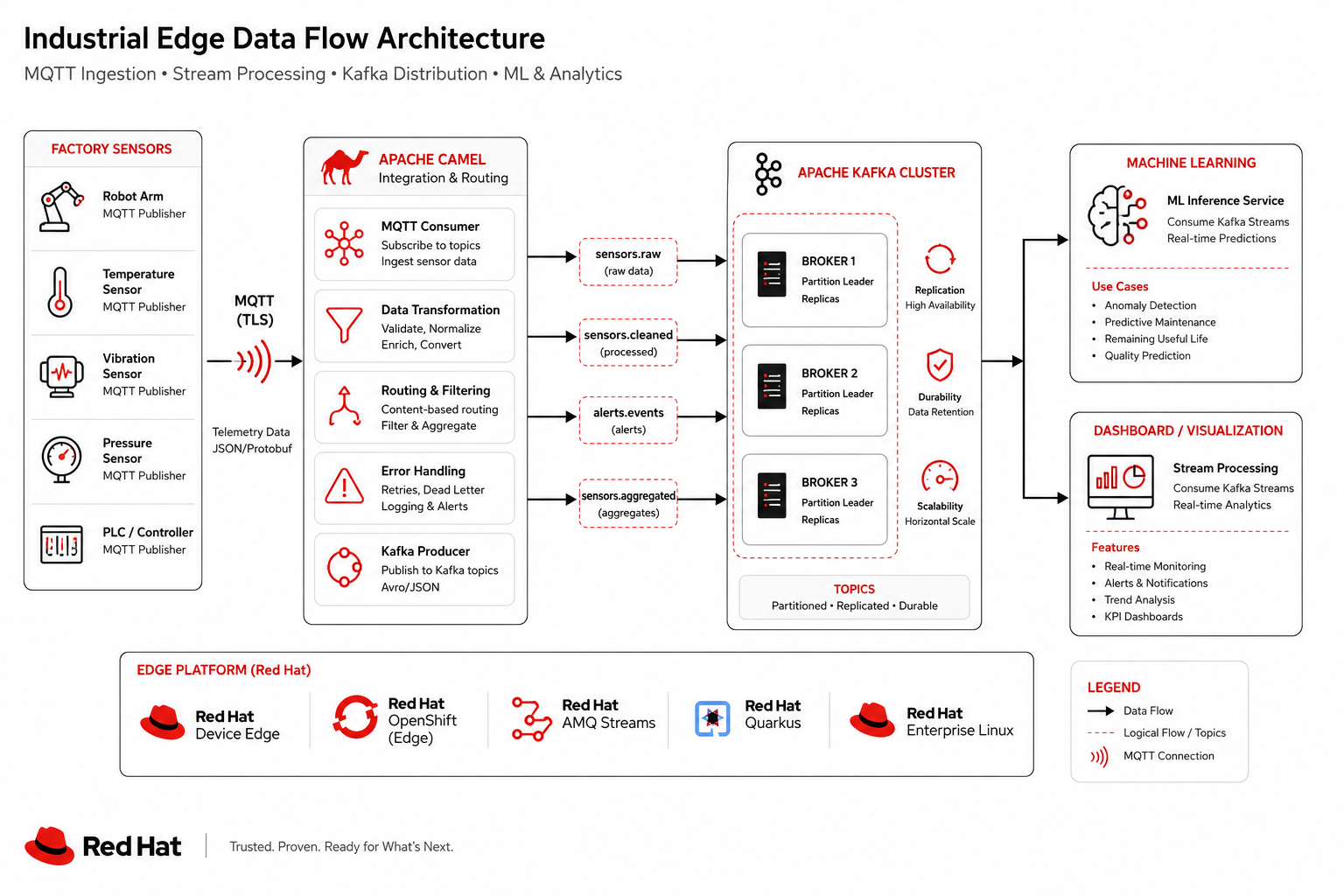
Telemetry path on each spoke; MirrorMaker replicates to the hub-centralized MinIO data lake.
Comparison with Red Hat Validated Patterns
The Multicloud GitOps validated pattern demonstrates fleet GitOps with OpenShift GitOps and ACM patterns that resemble this repository’s hub-push model: a declarative root Application, cluster grouping, and progressive rollout.
This platform extends that idea with Industrial Edge workloads, Service Mesh ambient, Connectivity Link, optional OpenShift AI, ACS depth, and Service Interconnect for cross-cluster service exposure – tuned for factory-style telemetry and east-west observability rather than only infrastructure provisioning.
Next → translate diagrams into installs via Getting Started / Deploy with ACM and GitOps, scaffold new edge instances via Scaffolding, then follow Observability once workloads expose Prometheus signals. For onboarding namespaces, see the Annotations & Labels Reference.